Perfecting Lambda Architecture with Oracle Data Integrator (and Kafka / MapR Streams)
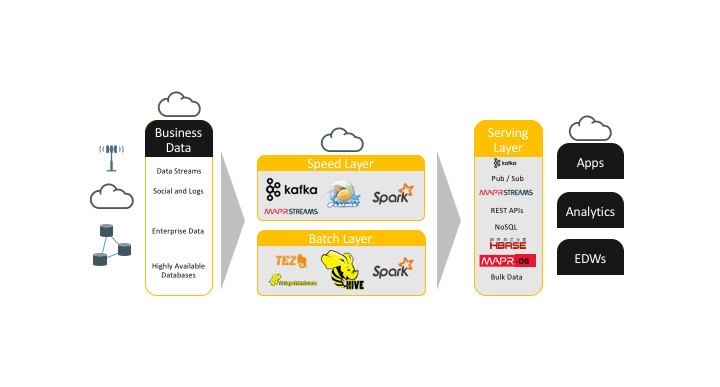
Republished by: MapR Technologies Datafloq ——- Introduction “Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch– and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online […]
Drilling into Data with Oracle Data Integrator

Apache Drill is “an open-source software framework that supports data-intensive distributed applications for interactive analysis of large-scale datasets”. Think of it as the one engine for of all that is relational and non-relational, almost. Drill can be considered as part of the “serving layer” in lambda architecture. It enables you to query data, using a highly sophisticated distributed engine that runs […]
Reverse Engineer MapR-DB with ODI

This is going to be a short write-up, a bonus to my previous post “Oracle Data Integrator & MapR Converged Data Platform: CHECK!“. MapR-DB client APIs can access both HBase tables and MapR-DB tables, it all depends on what you pass to its methods. So in case you need to reverse engineer your MapR-DB tables, […]
Hive, Partitions and Oracle Data Integrator

If you using Oracle Data Integrator (ODI) to load a set of results into a table with partitions and unable to, you’re in the right place. Partitions are good and needed, no need to talk about their benefits here. What I’m going to focus on is how to let ODI use them with a “dirty” […]
Oracle Data Integrator & MapR Converged Data Platform: CHECK!

MapR has their own Hadoop-derived software, a distribution that claims “to provide full data protection, no single points of failure, improved performance, and dramatic ease of use advantages”. For instance, MapR doesn’t rely on regular HDFS we’re all used to, but came up with MapR-FS, which works differently and provides substantial advantages over regular HDFS, […]
Moving Data Across Hadoop Clusters using Oracle Data Integrator
Today I came across this request: “We need to copy our data efficiently between two Hadoop clusters, via ODI. Can we?”. When it comes to ODI, I cannot think of a case where I ever said no, thanks to its modular architecture, flexibility and extensibility. While there is no “official” KM yet shipped with ODI […]