If you using Oracle Data Integrator (ODI) to load a set of results into a table with partitions and unable to, you’re in the right place.
Partitions are good and needed, no need to talk about their benefits here. What I’m going to focus on is how to let ODI use them with a “dirty” little trick. Is there some other way? I’m not really sure, so if you know please let me know via the comments area below, specifically using Spark as the execution engine.
NOTE 26.8.2016: The following is intended to be just a “workaround” and not an official solution, just to give you a hint which you may build on top of. If you applied Patch 22339136, the Spark part will not work. I’ll make sure to update this once I get a new way around it.
First things first, let’s have a look at how the partitioned table I’m going to use looks like:
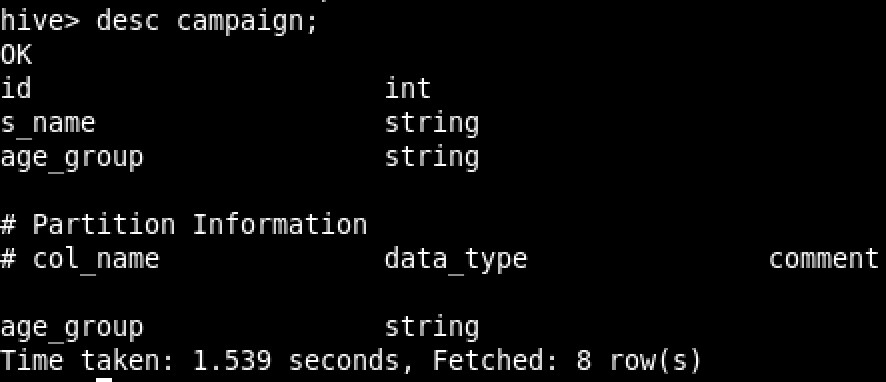
And the table from which I’m going to select data from:
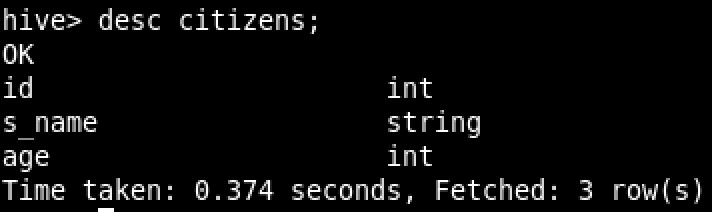
And the sample data set:
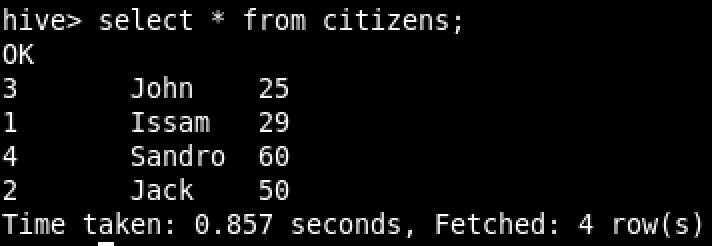
Let’s reverse engineer those two tables in ODI. The campaign table (which is partitioned on age_group) looks like the following:
Select the age_group column and remove it. Then go back to the “Definition” tab:
Here is the “dirty” little trick. In the Name and Resource Name boxes, add the partition part as shown. The #PartitionValue is a variable which I’ll create next so I can assign the partition value dynamically. If you wish, you can have it fixed. Now let’s create an ODI variable:
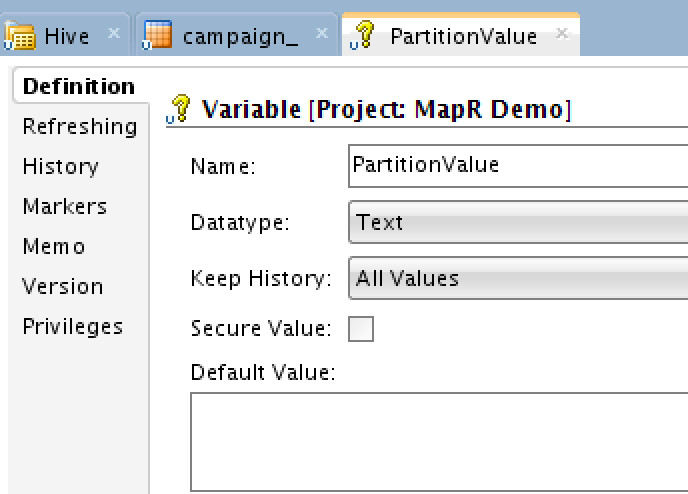
Nothing special, just another ODI variable, right? Cool. Now let’s create a mapping which will load data from our source table (citizens) to the target table (campaigns):
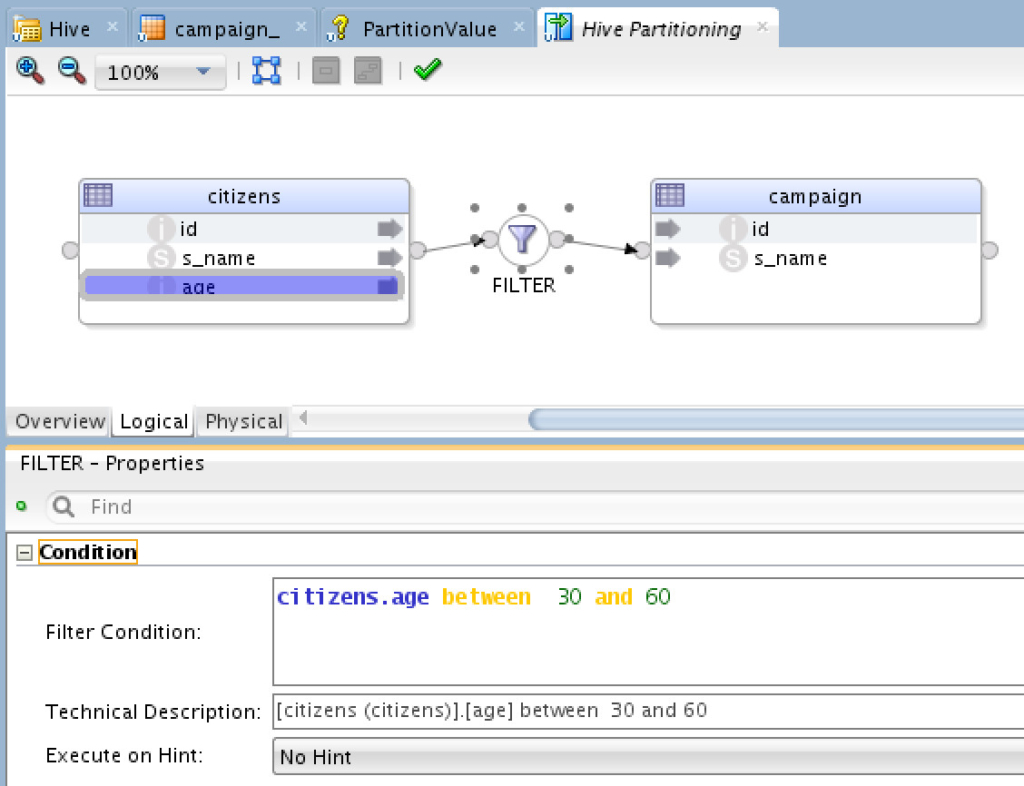
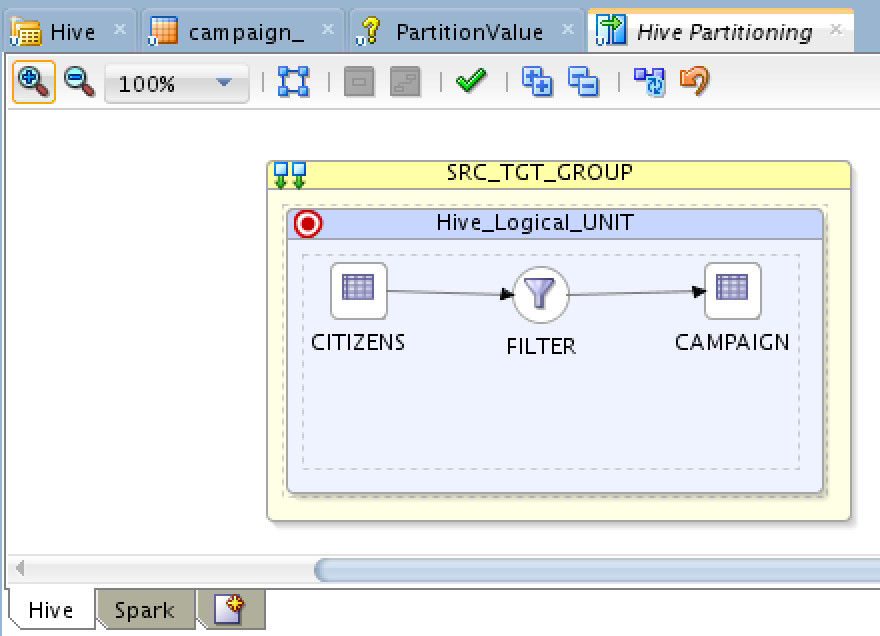
A simple mapping with a simple filter, now let’s configure the Physical implementation and create two implementations, one to be executed on Hive directly, and another via Spark. Here is the Hive one:
And here is another for Spark:
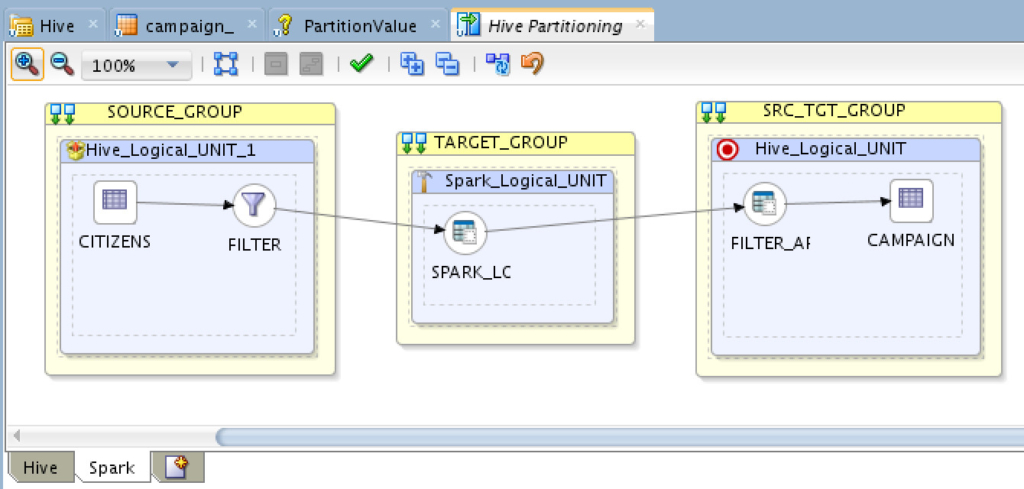
Same logical design, two different physical implementation, that’s one of the reasons behind ODI awesomeness. I wanted to make this a little more interesting and “truncate” the partition I’m going to load into, ONLY the partition. To do that, it’s same as you would do with regular mapping which truncate the whole table, here is an example for the Spark implementation:
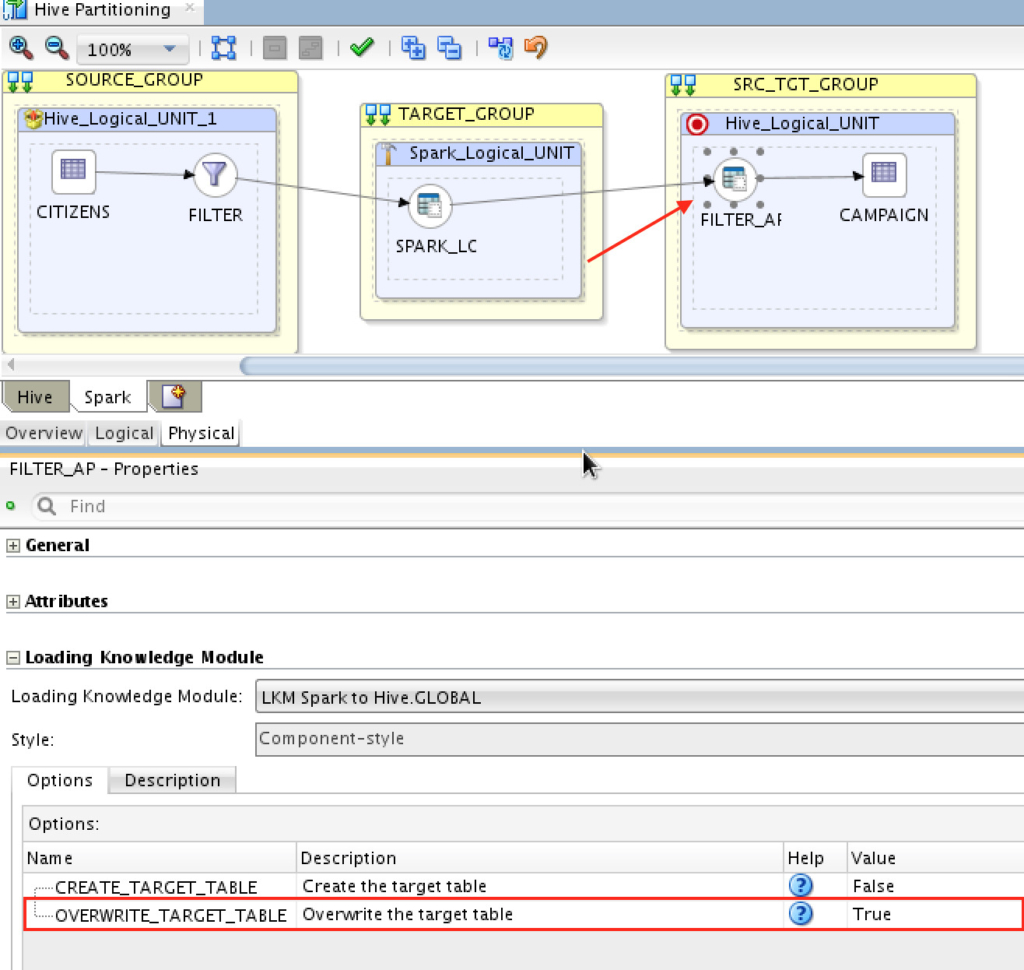
If you wish to have the same for Hive implementation (or other physical implementation you have), you need to specify that for each physical implementation.
That’s it. Now you may create a Package, generate and pass values dynamically or have a static one, it’s your call. Here is how it would look like:
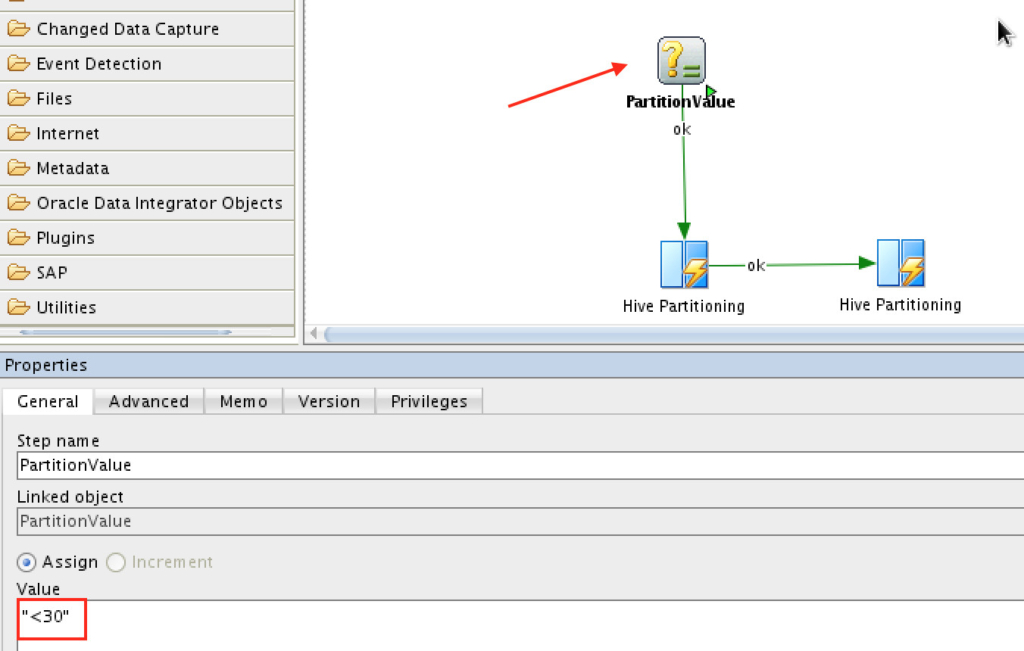
The above would load the data into “30-50” partition, run it. And the following one into “>30” partition:
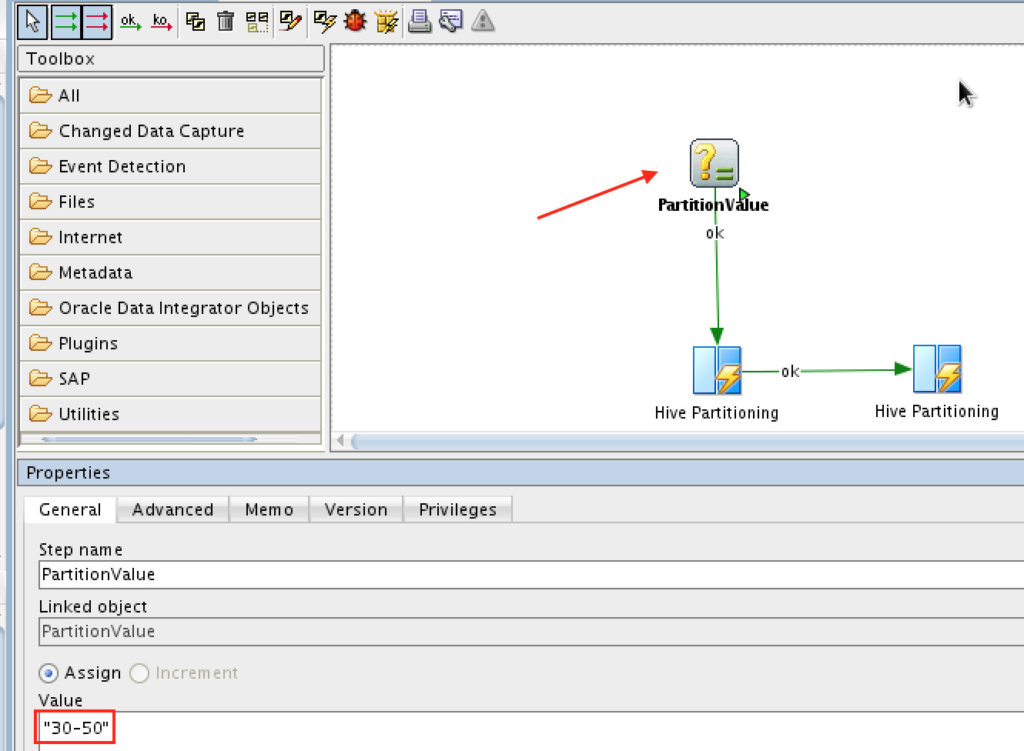
**NOTE: The values are between DOUBLE quotes, not a single one. If you specify single quotes, you’ll get a syntax exception with Spark**
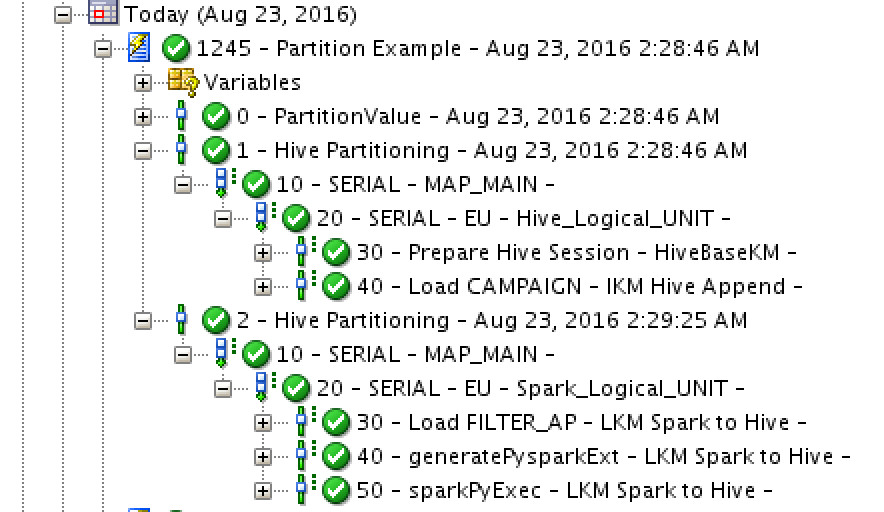
There are two mappings here, one executing on “Hive” and the other on “Spark”. Running the package was successful (on both partitions):
Querying the Hive table:
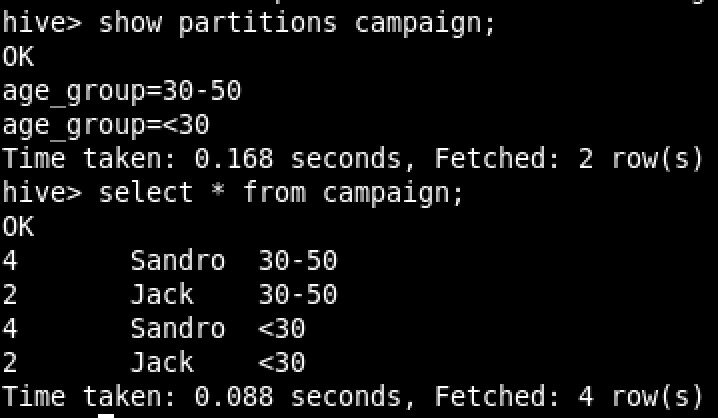
There you go, the partitions and the data!
Got any questions? Leave it in the comments area below.
Don’t forget to Like and Share 🙂
Are you on Twitter? Then it’s time to follow me @iHijazi