Apache Drill is “an open-source software framework that supports data-intensive distributed applications for interactive analysis of large-scale datasets”. Think of it as the one engine for of all that is relational and non-relational, almost. Drill can be considered as part of the “serving layer” in lambda architecture. It enables you to query data, using a highly sophisticated distributed engine that runs on top of Hadoop cluster, by executing industry-standard APIs such as ANSI SQL and ISO SQL data types. In simple words, you’ll be able to query multiple sources, join them, filter, aggregate and much more using the typical SQL (not customized) that you’re used to with RDBMS such as Oracle Database or MySQL.
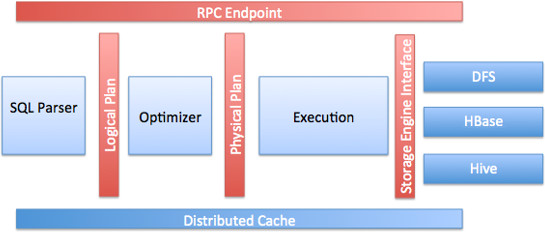
It’s not just another SQL-on-Hadoop kind of framework. If you ever thought of a seamless way to integrate your data sources without worrying if they are relational or not, structured or semi-structured (JSON, XML, etc…), being able to join your file-based data (i.e parquet format) , RDMBS (i.e Oracle database), HBase, MapR-FS and others on-the-fly, literally on the fly, without worrying about defining a schema, and get your results back in sub-second latency (depends, of course), then Apache Drill can be your answer.
SQL, Distributed Engine and Native Integration
Oracle Data Integrator (ODI), is a “pure” E-LT tool that allows users to integrate heterogeneous datastores natively wherever they reside, w/out moving data. One of ODI’s main differentiators is the ability to generate and run native distributed and optimized code on many RDBMSs as well as Hadoop without you having to worry about the “how-to”. It’s capable of generating SQL, Java, Python, Pig, and many more codes based on the desired integration technology.
Since Apache Drill “speaks” SQL, then ODI is capable of generating and executing Drill SQL queries for E-LT purposes. Or wait, should I say “ET-L”? “T-EL”? Or maybe D-L (Drill and Load)? Whatever you want you draw it in your mind, it’s massively distributed, native and requires NO property middle-tier engine.
In the following blog post I’m going to show you how ODI can integrate with Apache Drill just like any other technology or data source, execute SQL natively on it and get the best out of it for different use-cases. It’s a great example of ODI extensibility to adapt new technologies effortlessly. You’ll see how you may query and aggregate MySQL, MapR-FS (HDFS compliant), MapR-DB (HBase compliant), Apache HBase, and Hive in the same mapping, as if they all reside on the same engine. Thanks to Apache Drill for doing all the magic seamlessly and effortlessly. I’m pretty sure you may think of many ways to utilize this incredible feature, and start “drilling” faster to gain tremendous value!
It’s worth mentioning that Apache Drill is made for “querying” purposes, and not for storing. Meaning, you’ll be able to run the most complex query ever, but not insert/update the results anywhere. You may create a view, save results to file system maybe, but not into databases using Drill alone. Here comes another great advantage of ODI, being able to utilize the general-purpose SQL knowledge modules to insert/append/update relational targets.
Let’s get our hands dirty now and see how we can make that happen in ODI. I’ve utilized MapR’s Sandbox that comes with MapR’s 5.1 installed and configured, which I’ve previously customized for other blog posts. For this specific blog post, I only had to to install “Apache Drill”. Installing stuff on MapR cluster is simple and painless; a simple “yum install mapr-drill” is all you need.
Note: You may use other distributions or commodity clusters. It just happened that I have a MapR VM that runs perfectly with what I’m going to share next, plus the fact that I found many resources available online made by MapR.
Apache Drill Preparations
To install Apache Drill, I’d suggest following Apache Drill’s official online documentation, it’s very well structured and easy to follow. If you’re using MapR Sandbox (the one without Drill), like I do here, then you may want to follow their documentation.
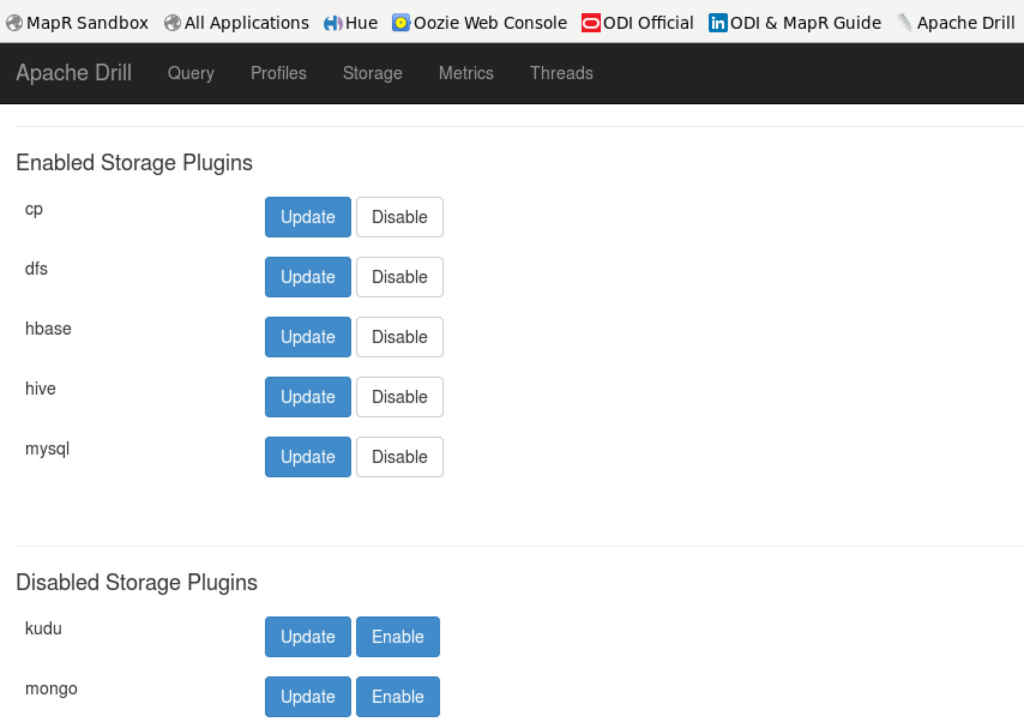
As Apache Drill enables you to query different engines and aggregate them via its own distributed engine, you need to define how to reach those engines. This is done via Apache Drill “Storage” concept/layer, allowing you to define as many sources as needed. This includes the ability to define file-system, HDFS, RDMB (i.e Oracle Database, MySQL), NoSQL (i.e HBase), Hive, etc… Full list of what’s supported can be found on Drill’s official documentation. For the purpose of this blog, I have enabled and configured the following storages:
- DFS: Being able to access data on HDFS/MapR-FS with different formats such as JSON, XML, CSV, Parquet and MapR-DB.
- HBase: To be able to access “flat” HBase tables. Note that for MapR-DB, we need to use DFS storage.
- Hive
- MySQL
- CP: This is the local file-system.
Oracle Data Integration Preparations
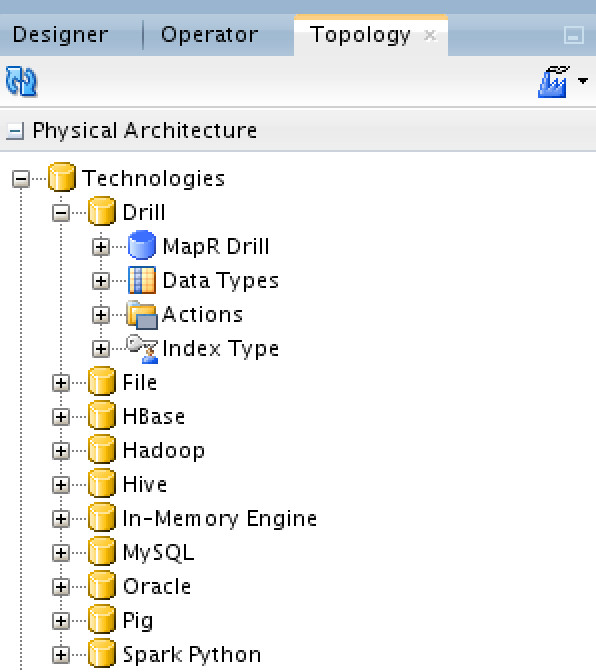
The very first thing you need to do is to create a new technology under the physical architecture area. You don’t need to create things from scratch with ODI, ever, thanks to ODI comprehensive out-of-the-box built-in capabilities. What I did was duplicating the “Hive” technology, renaming it to “Drill” and then refine it to accommodate Drill’s data types (which are pretty much the same) and refine its SQL keywords (again, pretty much the same with minor differences). Here is Apache Drill SQL Reference, which was my bible. You don’t, necessarily, have to do this, but I like to keep things neat. Once I had the technology ready, I created a data server under it and called it “MapR Drill”:
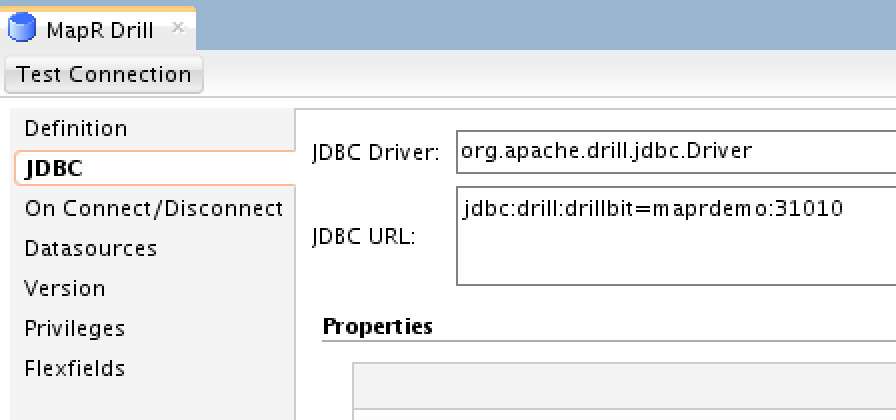
The “MapR Drill” data server utilizes “Apache Drill” JDBC driver and APIs:
Then you need to create physical schemas for each source that we need to “Drill” (the storages we’ve mentioned earlier), under Drill data server technology:
The “Definition” for each physical schema is very typical, and consists of having the “Schema” selected. This maps to “Storage” in Drill. The dropdown is populated automatically so you don’t have to second guess which one to select. Here is an example for MapR-DB (which I’ve customized previously in the dfs storage in Drill):
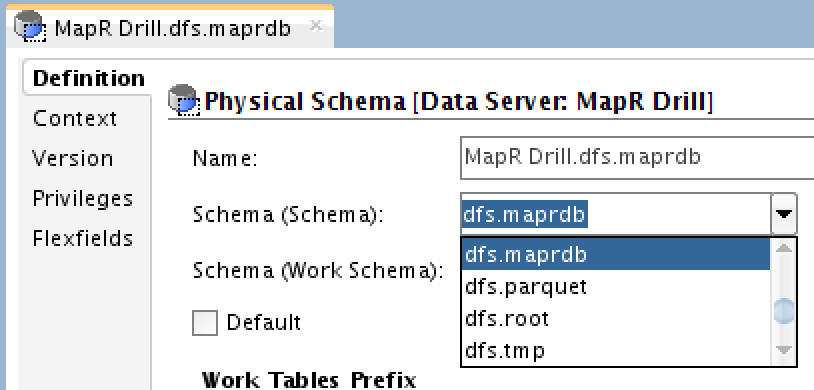
NOTE: Remember that MapR-DB is treated as “DFS”. For HBase, you need to select “hbase” which will get you the flat level tables in HBase (HBase is flat and has no namespaces, however, MapR-DB does).
Next you need to do the same things that you’d typically do with ODI: creating models, mappings and get things going. Note that you would need to “reverse engineer” your sources, possibly again, if you want to have Drill running the queries under its hood. Drill uses namespaces, and that’s how you point to a certain source (Hive, HBase, MySQL, etc…). If you use datastores that you reversed engineer using native connectors (say Hive, using Hive technology and physical schema), it won’t execute on Drill engine.
Reverse engineering those models are straightforward and don’t require any modification, except for the “d/fs” based ones. You need to select “RKM SQL” as knowledge module:
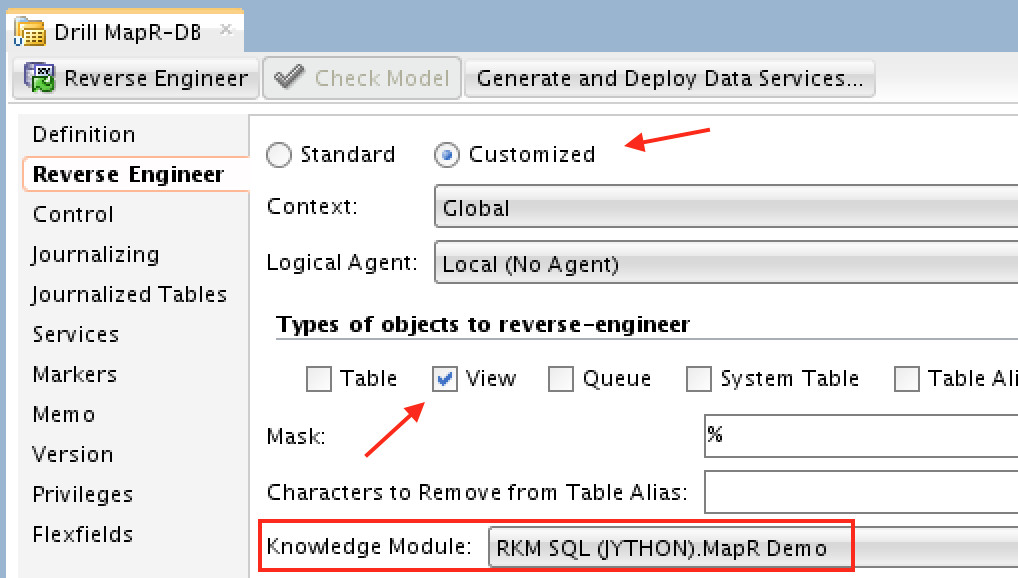
Notice that I’ve selected only “View” as type of object to reverse-engineer. Why? Good question! When you reverse-engineer Drill’s data models with ODI, Drill would do that by calling the underneath storage engine APIs, using ODI’s built in “generic” reverse engineering method. With data sources that has engines underneath (and metadata), there won’t be a problem. However with other data models, there would be. Creating views (flat simple views) in Drill would solve that problem. If, however, you’re feeling too creative, and want that to be seamless (without creating views on Drill first outside ODI), then maybe you’d consider customizing the RKM SQL to do that. I’ve got some ideas here, but its out of this blog’s scope.
That’s pretty much! Now you should be able to use your drill datastores as sources in your mappings, and run queries/aggregations/etc natively on Apache Drill.
Executing Apache Drill Mappings
I’ve created a few test-cases to show the capability of Apache Drill on joining and aggregating different sources on its own engine with sub-second latency using the generic SQL knowledge modules that are shipped with ODI, to be specific LKM SQL to SQL in the following case. I didn’t have to re-write or update a single line in those KMs. In the following example, I’m joining, filtering and aggregating MapR-DB, MySQL, MapR-FS, Hive and MapR-DB on Drill, and loading the result into MySQL:
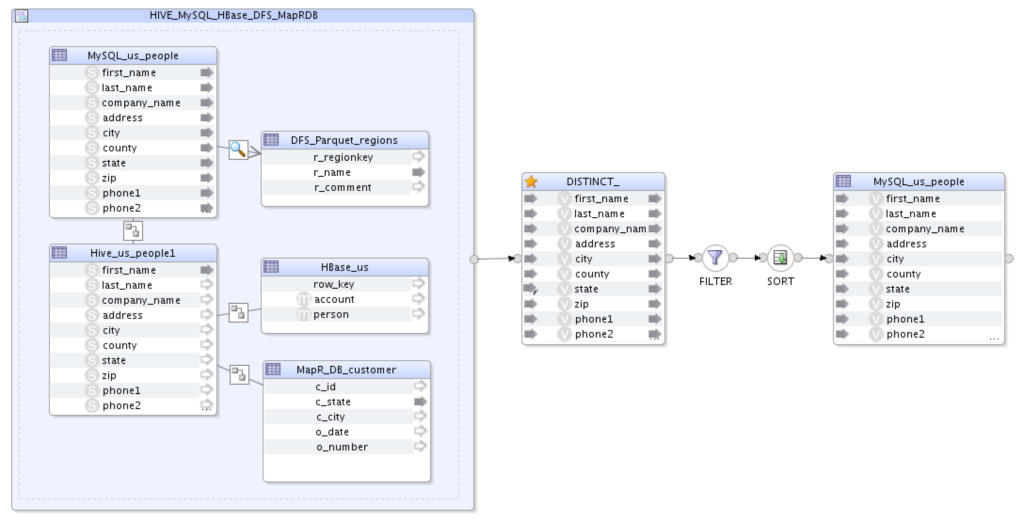
And here is the physical view of the preceding mapping:
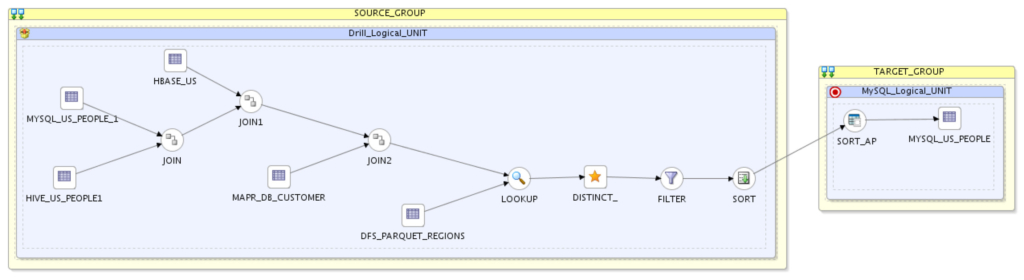
Pretty awesome, isn’t it? Executing the preceding resulted in ODI generating the needed code to be executed on Apache Drill engine, natively, and loading the results into MySQL in few seconds. Executing the same using batch-based engines (like MapReduce/Pig/Hive/etc…) would definitely take much longer.

Conclusion
Apache Drill is truly flexible, agile and SQL user-friendly engine that helps you “automatically restructure a query plan to leverage datastores internal processing capabilities” in real-time to join/filter/aggregate/manipulate/etc different sources together under its distributed engine. Having that said, combining it with a native E-LT tool like Oracle Data Integrator shall help to gain much faster time to value and allow you to utilize ODI’s massive integration capabilities. This blog marks another successful open-source framework seamless usage with ODI.
Don’t forget to Like and Share!
Follow me @iHijazi to stay updated with everything that I share.