MapR has their own Hadoop-derived software, a distribution that claims “to provide full data protection, no single points of failure, improved performance, and dramatic ease of use advantages”. For instance, MapR doesn’t rely on regular HDFS we’re all used to, but came up with MapR-FS, which works differently and provides substantial advantages over regular HDFS, according to MapR.
Oracle Data Integrator (ODI) is a heterogeneous solution that works seamlessly in integrating major big data components such as HDFS, HBase, Hive, Spark, Pig, etc… It has been certified to work with distributions such as Cloudera, Hortonworks and even commodity clusters. That being said, it’s been questioned many times if ODI can actually work with MapR’s platform, given the fact that MapR has some property components (such as MapR-FS and MapR-DB).
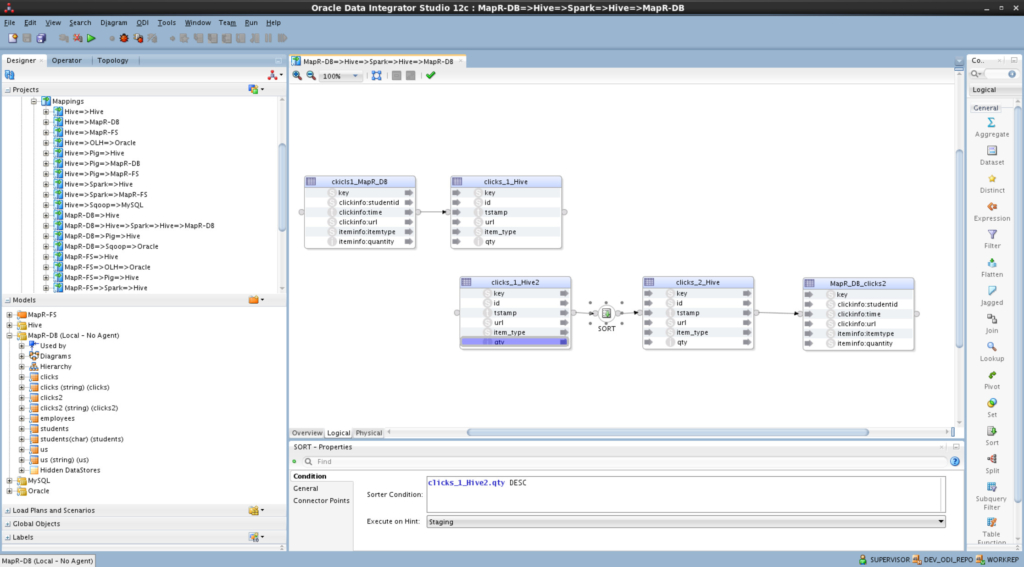
I’m writing the blog to “nip in the bud”. I’ve personally tried and tested MapR’s distribution and ensured its compatibly with ODI, FULL compatibility, with about 22 use-cases. The process includes setting up environment paths, few updates and configurations. Going through this blog will help you understand the steps you need to make in order to get ODI up and running with MapR Converged Data Platform.
I’ve used MapR’s Sandbox 5.1 which comes pre-configured with single node “cluster” and has most of their components installed. I’ve done modifications to the VM and installed Oracle’s goodies on it and other things, however I’ll only cover the relevant ones. If you want to have ODI work on your own cluster, the assumption here would be that you have a properly installed and configured MapR cluster; that’s important!
MapR Converged Data Platform
While the Sandbox comes with MapR’s 5.1 platform installed and pre-configured, I had to do some upgrades and change few settings. The following are the relevant components that I’ve used and their version (possibly after upgrade/clean installation):
- Hadoop 2.7.0 (label 1602)
- HBase 1.1.1 (label 1602)
- Hive 1.2 (label 1607)
- Oozie 4.2.0 (label 1607)
- Pig 0.15.0 (label 1602)
- Spark 1.6.1 (label 1602)
- Sqoop 1.4.6 (label 1607)
There are other components that are installed, but are irrelevant to ODI integration use-cases. And just to confirm, I’ve used MapR-DB version of HBase for the use-cases.
In the following sections, I’ll go through the changes I’ve made to make the platform “ODI ready”.
Java
I’ve switched MapR’s Java version to Oracle’s JDK 8u101. That’s going to be needed later on for ODI as well.
Oozie
I modified one of “oozie-site.xml” properties as the following:
- Property: “oozie.service.HadoopAccessorService.supported.filesystems”
- Value: hdfs (previously it was mapr)
Don’t worry, you’re still using MapR-FS, this is just for “casting” purposes and to avoid exceptions.
If you’re familiar with Oozie, you’d know that it has a shared library folder/s that has relevant framework jars (i.e pig, spark, etc…). Those jars are used to run each and every Oozie task. While most of them are complete, some additions were needed in order to have ODI mappings complete successfully using Oozie as an agent. The shared library folder/s are located under Oozie home installation with names like “share1” and “share2”. On your cluster, you probably need to update both/all share folders for HA reasons, I believe.
Under Pig folders (pig and pig-2), I’ve made soft link (ln -s) for “hive-site.xml” and some of HBase jars (which can be found under HBase home lib path):
- hbase-client-1.1.1-mapr-1602.jar
- hbase-common-1.1.1-mapr-1602.jar
- hbase-protocol-1.1.1-mapr-1602.jar
- hbase-server-1.1.1-mapr-1602.jar
Under HCatalog folder, I’ve made a copy (you may ln -s) for two missing jars in HCatalog folder (which is under Hive home path):
- hive-hcatalog-core-1.2.1-mapr-1607.jar
- hive-hcatalog-pig-adapter-1.2.1-mapr-1607.jar
**NOTE: Once you’re done, do not forget to run “oozie admin -sharelibupdate” command to update and apply your changes.
Spark
I’ve made a soft link (ln -s) for “hive-site.xml” under Spark’s conf directory.
MapReduce
I’ve made soft links (ln -s) for 4 of Hive’s jars under maprdeuce directory (typically under “../hadoop-2.7.0/share/hadoop/mapreduce/”. These jars are:
- hive-serde-1.2.0-mapr-1607.jar
- hive-metastore-1.2.0-mapr-1607.jar
- libthrift-0.9.2.jarhive-exec-1.2.0-mapr-1607.jar
Sqoop
I’ve copied Oracle JDBC jar into Sqoop’s lib path. You may want to do the same if you are going to do any Sqoop/Oracle related mapping.
Why all of the above is necessary?
Good question! MapR paths structure is slightly different from other conventional Hadoop distributions. Having some jar files, for example, copied or soft linked rather than adding them to some environment variable would cause conflict with other dependencies or sometimes not even picked up which would cause all of kind of exceptions that you don’t want to experience, trust me.
**NOTE: Do not forget to restart your Hadoop services once done, mainly Namenode, Oozie and Resource Manager.
Oracle Data Integrator
Now we’re done with cluster configuration, let’s have a look on what’s needed to be configured on ODI, the version I’ve used is 12.2.1.0.0. Generally, if you want to run/schedule ODI mappings (jobs), you’d use either “Local / No Agent”, “Standalone Agent” or “Java EE Agent”. For big data, you may use the preceding agents as well as “Oozie” agent. I’ll show you how to configure Standalone and Oozie agents shortly.
**NOTE: Some of the test-use cases utilizes Oracle Hadoop Loader (OLH) to load data efficiently from big data sources into Oracle Database. For that purposes, I’ve downloaded “Oracle Hadoop Loader (OLH) 3.6.0”.
Studio
ODI studio (client) picks up shared jars from a configuration file that is located under the user account’s path. In Linux, the path would be “/home/<USER>/.odi/oracledi/userlib/additional_path.txt”. The following content has been added to that file in order to get ODI reverse engineer “MapR-DB” using (Local / No Agent); the only possible way I could find to have everything else works:
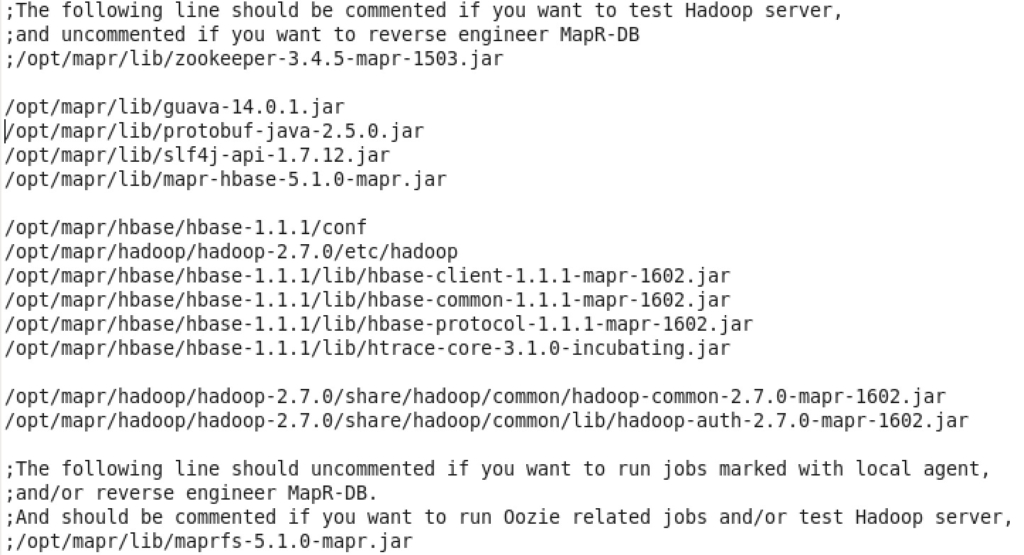
That little guy “maprfs-5.1.0-mapr.jar” causes some trouble if it’s presented in the classpath. Hence, comment/uncomment it as needed.
**NOTE: You may add those paths using wildcard to Standalone agent properties file or system wide environment variables, but that would cause some integration scenarios to fail.
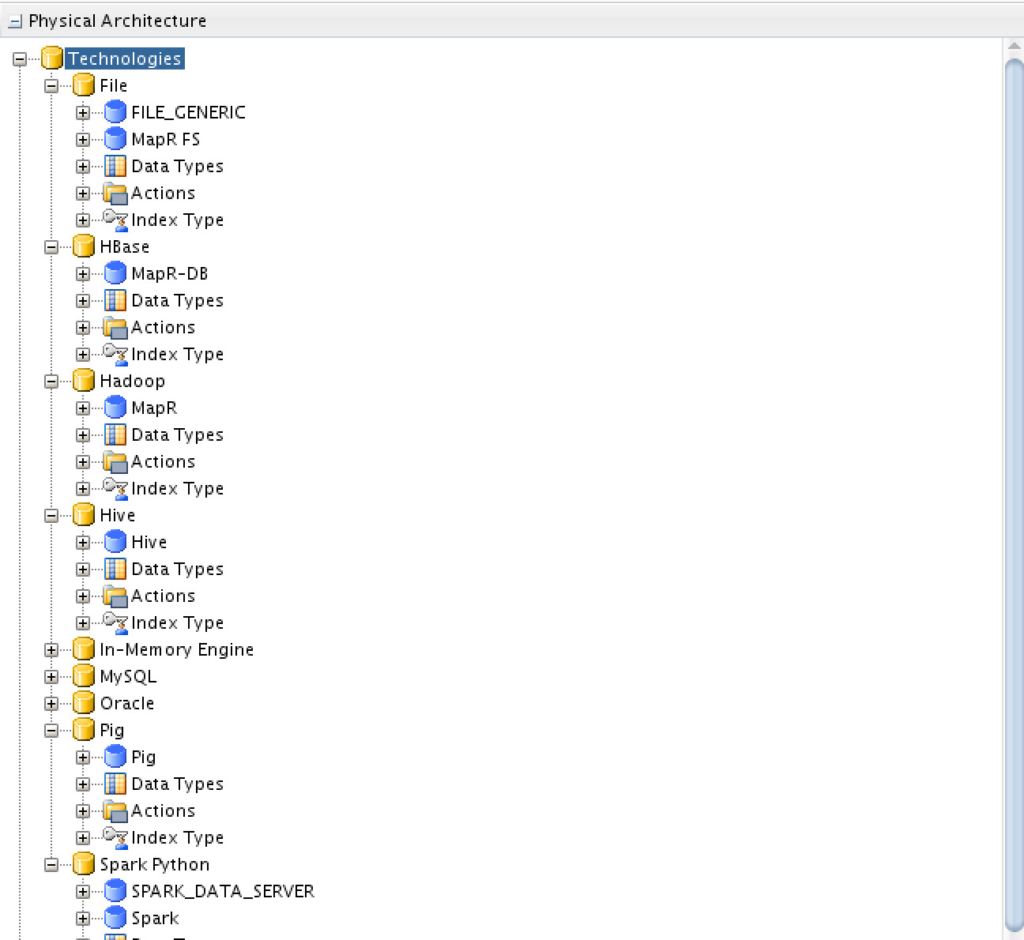
Physical Components
The following components have been configured to work with MapR’s platform:
Hadoop Data Server

Nothing special here, you need to put your platform credentials, HDFS Name Node URI (under the hood this is MapR-FS), Resource Manager URI, define ODI HDFS Root path in your MapR-FS and add class paths as shown.
The ODI HDFS Root is the path where ODI will add its needed dependencies and configuration to run its mappings. Having that said, once you define all of those variables, you need to initialize ODI’s path. That can be done by simply clicking on “Initialize” button”.
MapR-FS Data Server
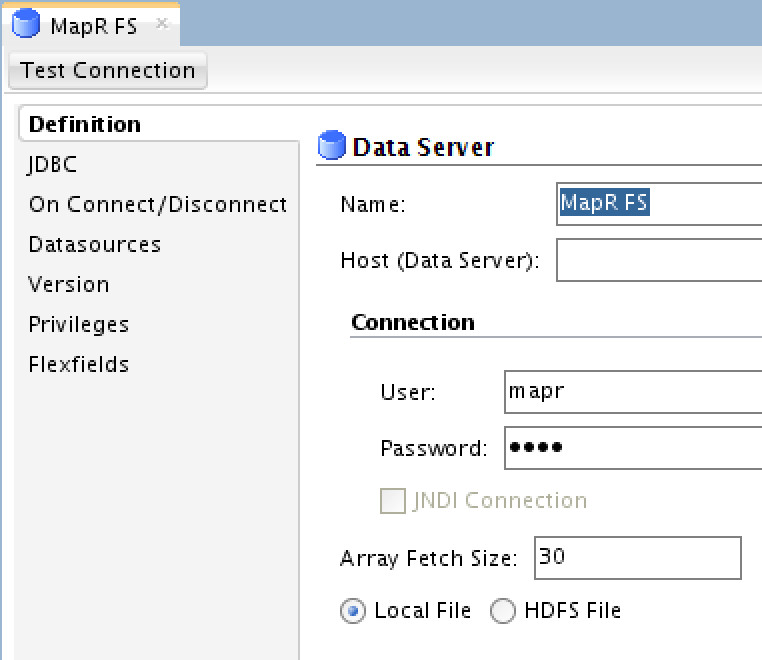
You need to provide your MapR’s cluster credentials, and then click on “JDBC” tab:
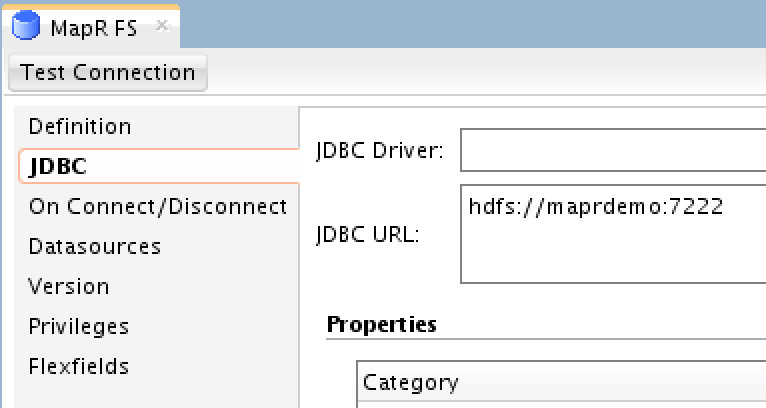
Under “JDBC” tab, you only need to provide the JDBC URL, which is the Namenode URI. Note that you cannot “Test Connection” for this data server.
MapR-DB
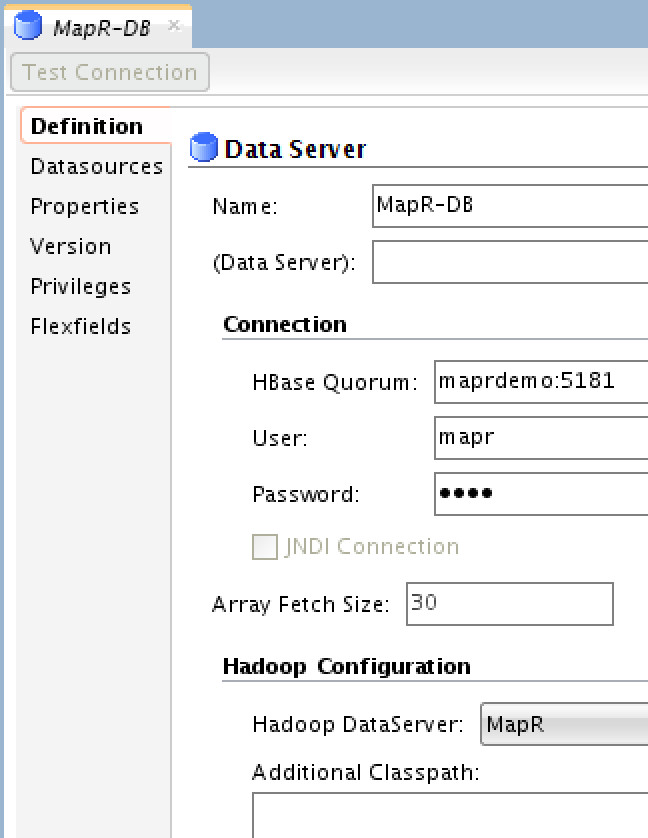
Simple configuration, just provide the HBase Quorum (that’s Zookeeper URI), MapR’s credentials and select the “Hadoop Data Server” you previously created, in my case it’s called “MapR”.
Hive Data Server
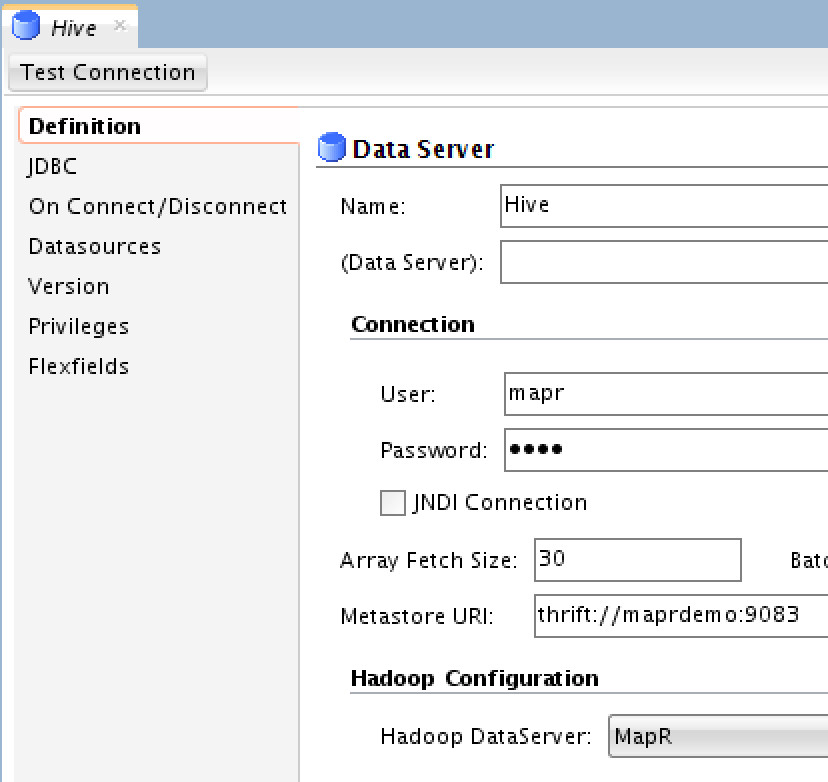
For Hive, you need to provide MapR’s credentials, Metastore URI (the thrift server) and choose the Hadoop Data Server you’ve previously created. Next you need to edit the JDBC connection details under “JDBC” tab:
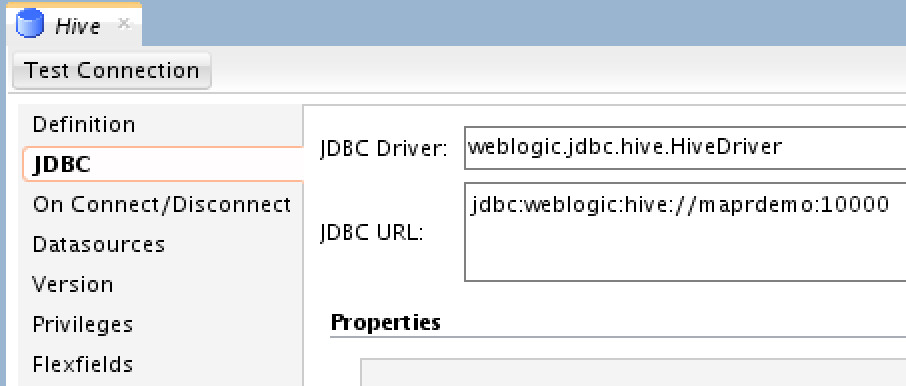
Choose the appropriate JDBC Driver (ODI comes with Hive driver, but you’re free to use MapR’s or any other), and the JDBC URL as shown.
Spark Data Sever
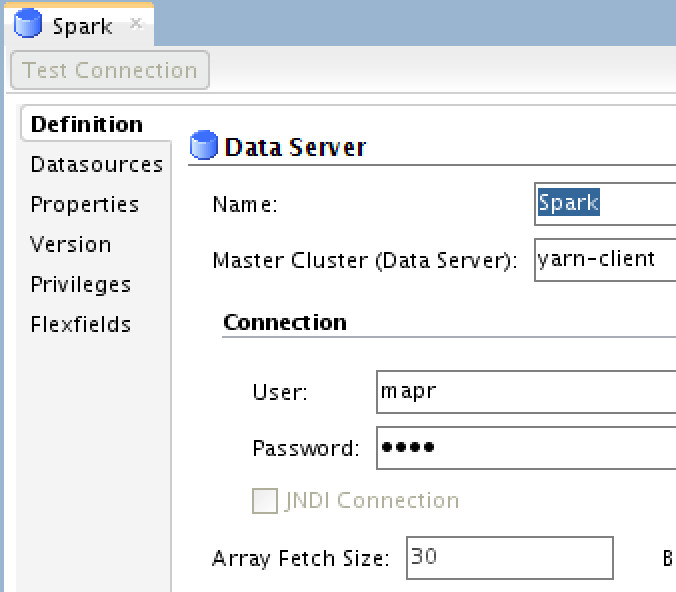
You need to define the execution/deployment model in the Master Cluster property, and MapR’s credential.. Next you need to define some specific Spark variables under the “Properties” tab:
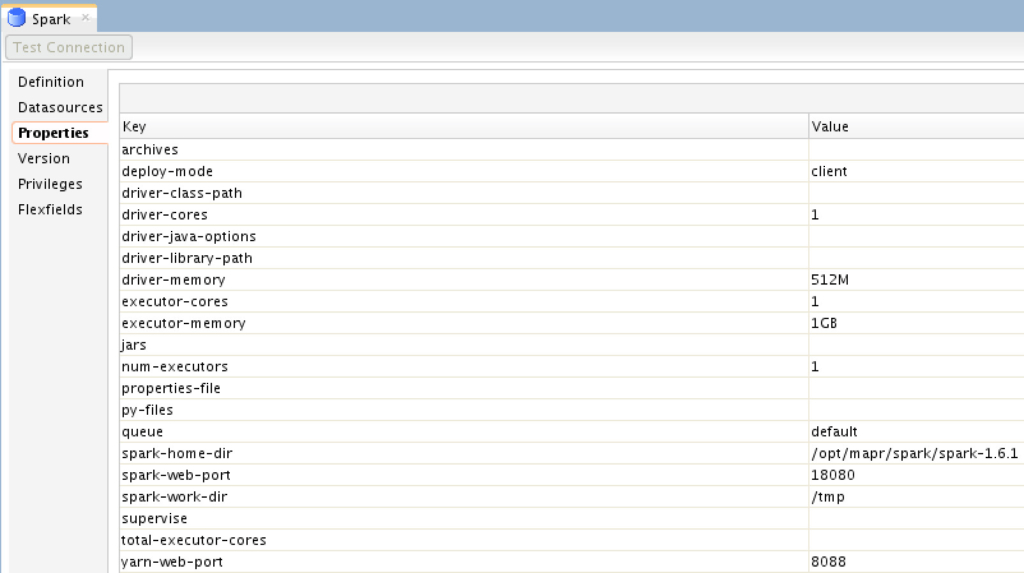
The most important variables here are the “spark-home-dir”, “spark-web-port”, “yarn-web-port”, “deploy-mode” and “queue”. The rest are pretty much for optimization, which you probably need to consider.
Pig Data Server
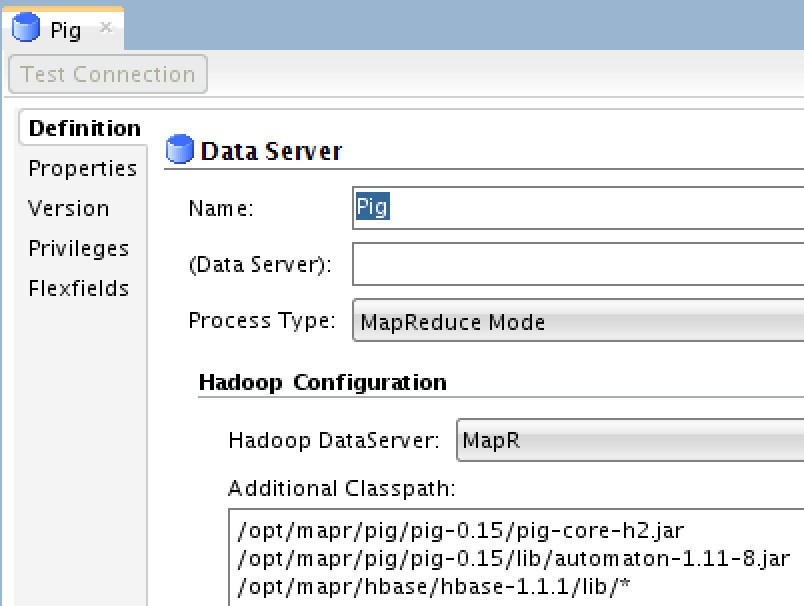
You need to define the “Process Type” as “MapReduce Mode”, select the Hadoop Data Server which you previously created and add additional classpath as shown. Next you need add some specific Pig properties under the “Properties” tab:

You need to define the thrift server URI and include additional pig jars which are needed for specific pig executions.
Standalone Agent
ODI Standalone agent is fully configurable and customizable, meaning that you may have your agent using independent Java settings and environment variables. From ODI point of view, there is nothing special configured in the agent itself as you may see in the following image:

Now, when you start an agent, there is a script executed to set Java settings and environment variables, the script file name is “instance.sh” and can be found under “<ODI_HOME>/user_projects/domains/<DOMAIN_NAME>/config/fmwconfig/components/ODI/<AGENT_NAME>/bin”. I’ve added the following content to that file:
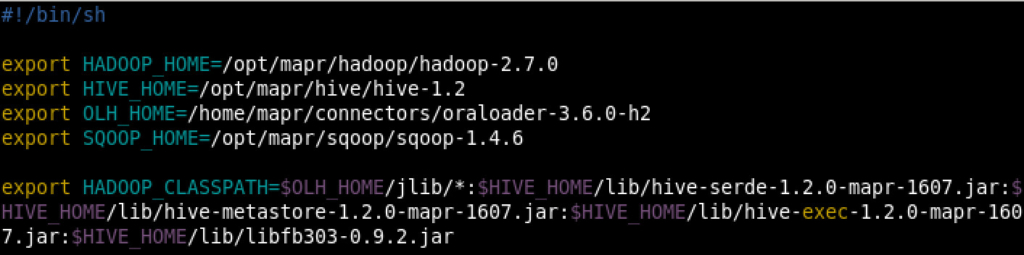
Simple and clean. Those variables are needed to run different ODI big data related mappings on MapR’s.
Oozie Agent
Lastly, if you want to use Oozie agent to orchestrate and execute your mappings, you need to create one with the following options:
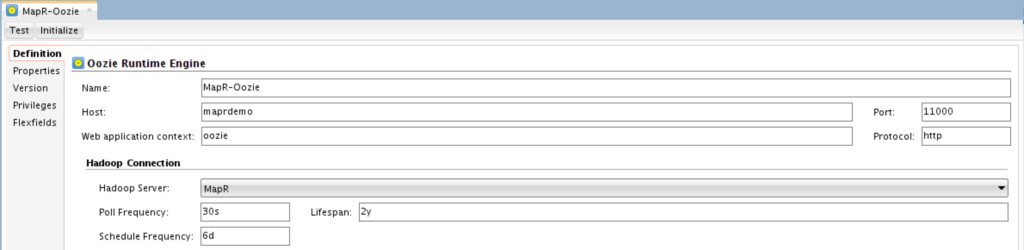
What you need to define here is the “Host” name/IP where Oozie is running, its Port (the default one is 11000), Web Application Context and select the Hadoop Data Server which you previously created. Once you enter all the needed information, you need to initialize it by simply clicking on “Initialize” button. Initialization basically add all ODI’s dependencies to MapR-FS relevant paths.
Just like Oracle’s agent has a configuration file that includes the needed environment variable, Oozie does as well. This file is called “odienv_config.properties” and is located in MapR-FS under the path which you’ve used to initialize your Hadoop Data Server (HDFS Root Path). If you scroll up, that would be “/user/mapr/odi” in my case. So this “odienv_config.properties” would be located under “/user/mapr/odi/odi_12.2.1/userlib/”. I’ve edited the content of that file to look like the following:
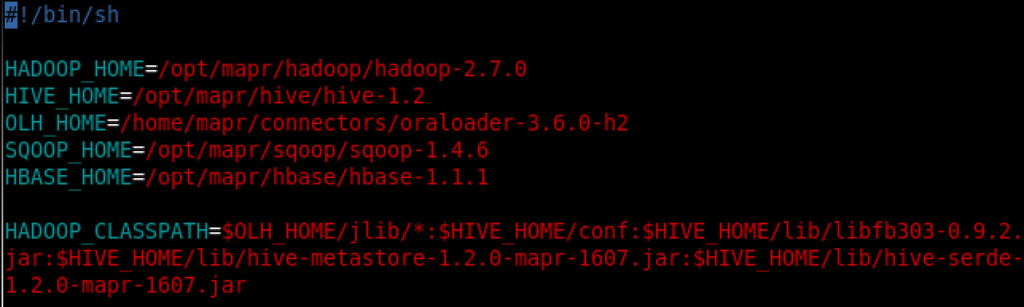
Pretty much same as “instance.sh” for ODI Standalone Agent.
That’s it! You are now ready to start using ODI.
Use-Cases
I’ve tried (and did) to cover all possible scenarios which I can think of to make sure that ODI runs flawlessly with MapR’s.
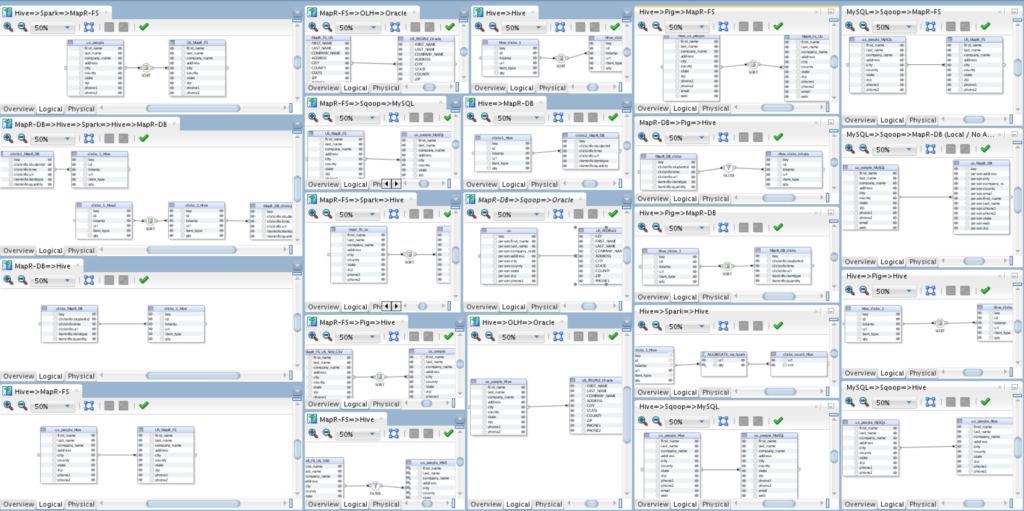
22 use-cases that cover all kind of possible integration combinations between Hive, Pig, MapR-DB, Spark, MapR-FS, Sqoop, MySQL Database, Oracle Database and Oracle Hadoop Loader. And the results are:
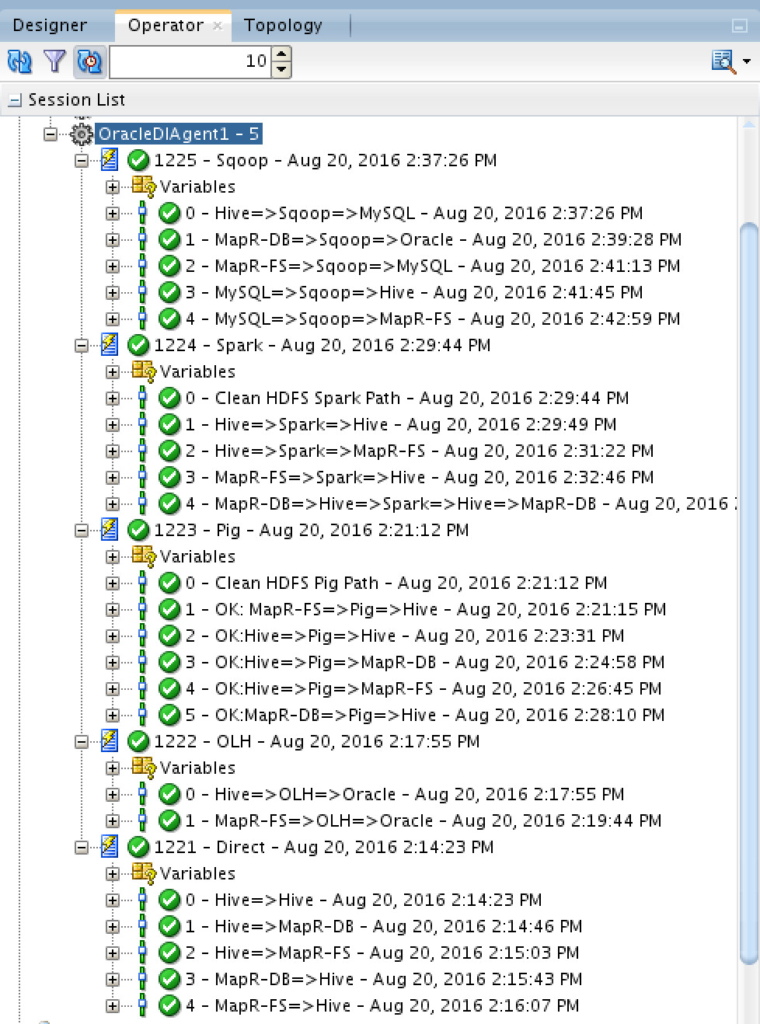
Oh yes, they are all green. And for Oozie Agent:
Also, very greenish! Have you noticed that I’m still in ODI? Yes, you can get the status and logs without leaving ODI studio. But if you prefer Oozie’s web console, then:
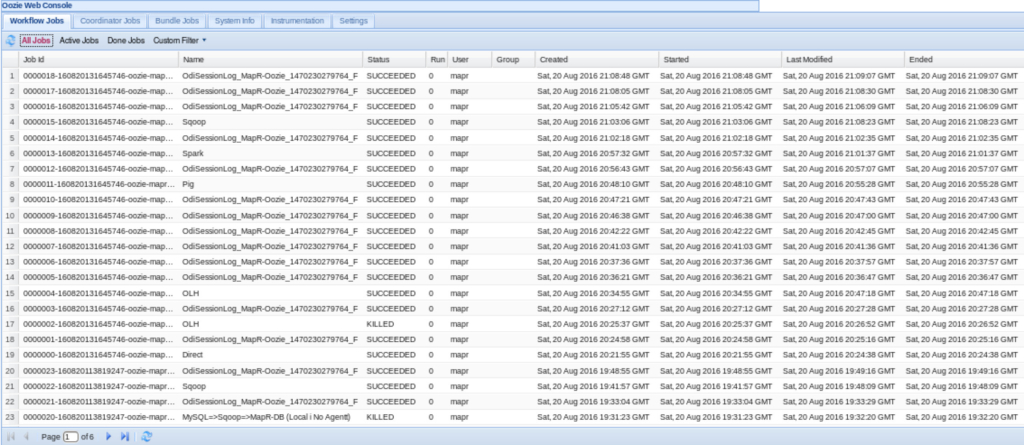
And Resource Manager:
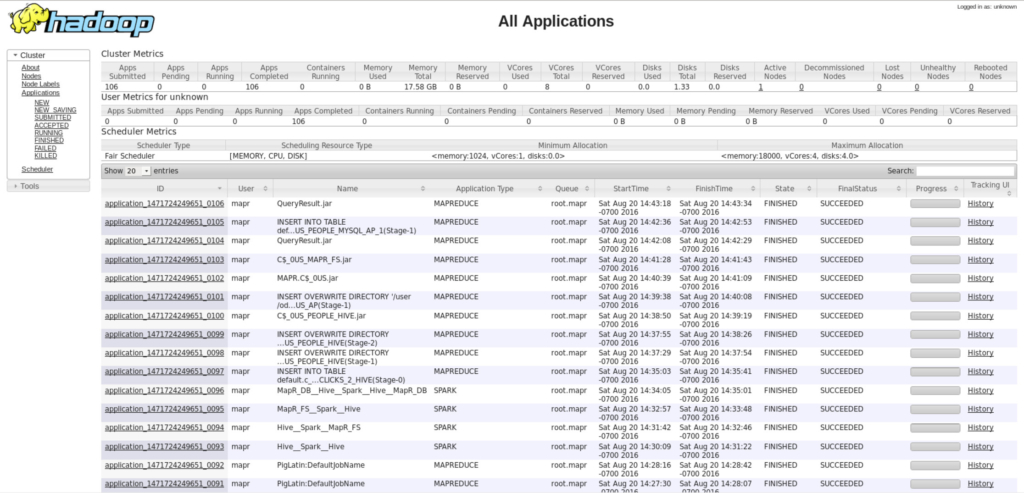
Conclusion
Oracle Data Integrator is a truly open and heterogeneous solution. I was able to run native E-LT jobs on MapR’s distribution and utilizes the optimization they applied the same way I’d on any other Hadoop distribution.
Got any questions? Leave it in the comments area below.
Don’t forget to Like and Share 🙂
Are you on Twitter? Then it’s time to follow me @iHijazi