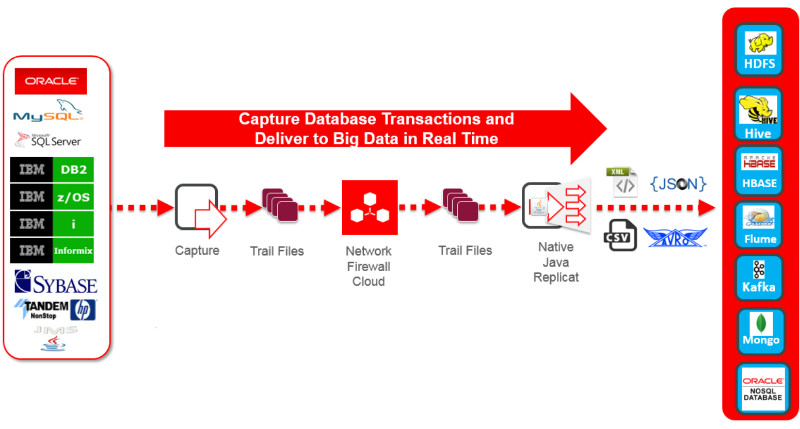
“Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real-time, without impacting the performance of source systems. It streamlines real-time data delivery into most popular big data solutions, including Apache Hadoop, Apache HBase, Apache Hive, Apache Flume and Apache Kafka to facilitate improved insight and timely action.”
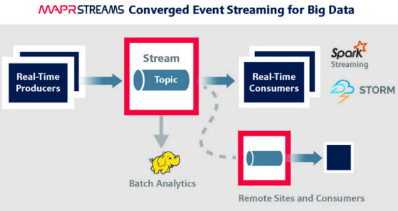
MapR Streams is similar to Kafka, or in fact is MapR optimized version of Kafka. According to MapR, the difference between Apache Kafka and MapR Streams is that it has “proven enterprise features such as global replication, security and multi-tenancy, and HA/DR, all of which it inherits from the MapR Converged Data Platform”. In other words, it’s their own “optimized version” of Apache Kafka which works under their distribution’s, MapR, umbrella. Moreover, it’s actually much easier to manage MapR Streams than Kafka!
I’m writing this blog to show how you can use Oracle GoldenGate to stream transactional data into MapR Streams by using the same configuration as you would do with Apache Kafka. The test that I’ve done basically captures transactions from Oracle Database and delivers them into MapR Streams. In real life, the source can be ANY database that’s supported by Oracle GoldenGate.
To get your hands dirty with the commodity Apache Kafka version and GoldenGate, you may want to go through Oracle’s tutorial “Tame Big Data using Oracle Data Integration“, where you’ll get the chance to learn how to use Oracle GoldenGate and also Oracle Data Integrator with several Big Data frameworks.
In my test I’ve used the following VMs:
- Oracle Big Data Lite VM 4.4: it has some necessary “stuff “ that I need to simulate the experience of having Oracle GoldenGate stream (produce) data into MapR Streams. It can be found here.
- MapR Sandbox 5.1.0: you can get it here.
Because MapR Streams utilizes Kafka version 0.9.0, you need to use Oracle GoldenGate for Big Data 12.2.0.1.1, which can be downloaded from here. Warning: previous versions WILL NOT work.

For capturing from Oracle Database, I’ve used Oracle GoldenGate for Oracle which is already shipped and installed in the VM. The parameter file for the source, Oracle Database, looks like the following:
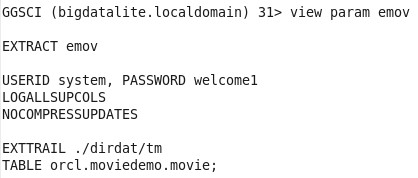
Nothing special here, a simple capture process for one table. I didn’t create a pump process in my test because everything is on the same VM, so I’ll just have my target replicate read the trail file generated from this capture/extract process.
At this point, I’ve started my extract and it was ready to capture any committed transaction in the defined table. Next thing I did was installing MapR client libraries, so that Oracle GoldenGate for Big Data can use them to connect to MapR Streams server. On the Oracle Big Data Lite VM, I’ve added MapR repository (as a file) to the Yum repository folder:
Here is the content for your reference:
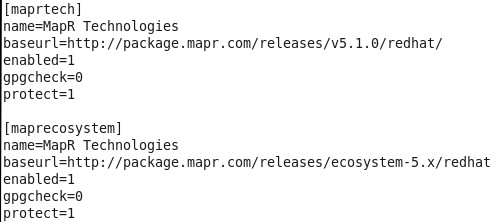
And then installed MapR client, to be used by Oracle GoldenGate:
yum install mapr-client
At this point, you need to configure MapR client, which is relatively easy. The guide for that can be found here.
**If you are installing Oracle GoldenGate on MapR cluster (or Sandbox) which has MapR’s library, then you may skip the previous step.**
After that, I configured Oracle GoldenGate for Big Data replicat process (which I’ve downloaded from edelivery and installed on the VM in the very first step). Here is a glance of the parameter file:

Again, nothing special here, except that we’re pointing to maprstreams.properties file. The content of this file is:
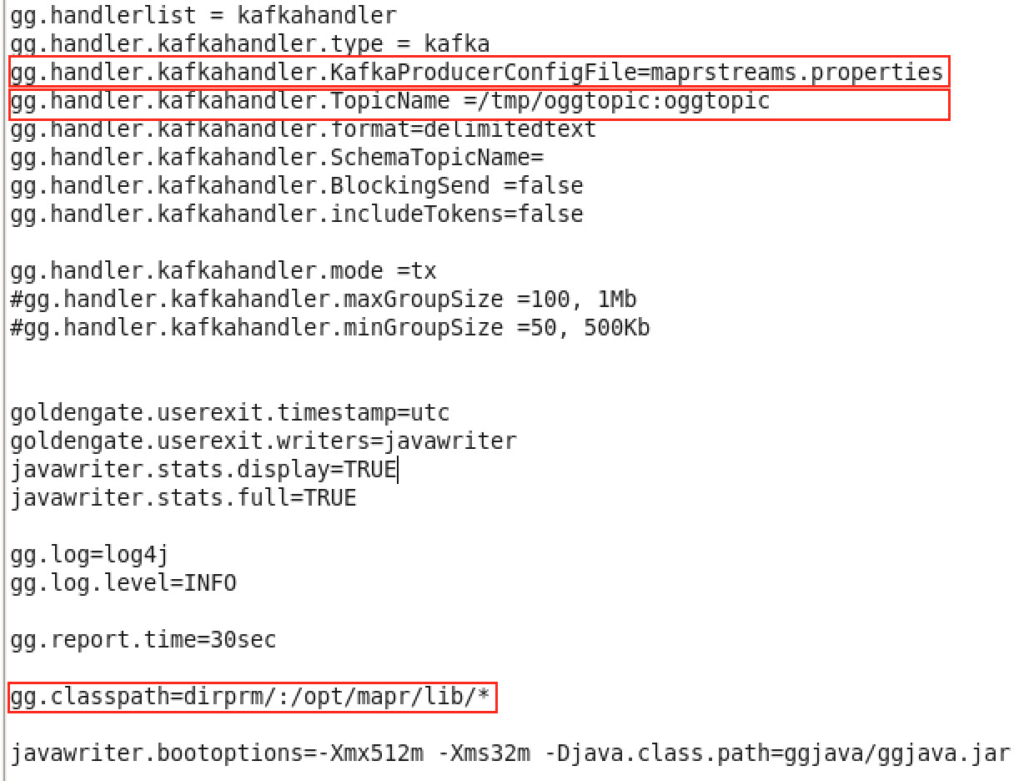
Here are some interesting variables that you need to pay special attention to:
1. TopicName: As you may notice, is unconventional and has a path before it. That is the namespace that will be used on the MapR-FS for this topic, oggtopic. More on that later…
2. classpath: It points to MapR client library which we previously installed via the yum commands.
3. KafkaProducerConfigFile: This file has a configuration related to the MapR producer.
**NOTE: MapR client can uses both commodity Kafka API or its own (MapR Streams). The “switch” here is when you provide the topic name, if it has namespace like above, then MapR Streams API is triggered, if it’s using simple topic name, the Kafka’s API is triggered**
The rest of the parameters are basic ones and are part of the template file that is shipped with Oracle GoldenGate installation.
Now, let’s have a look at the maprstreams.properties file which I’ve mentioned in point #3:
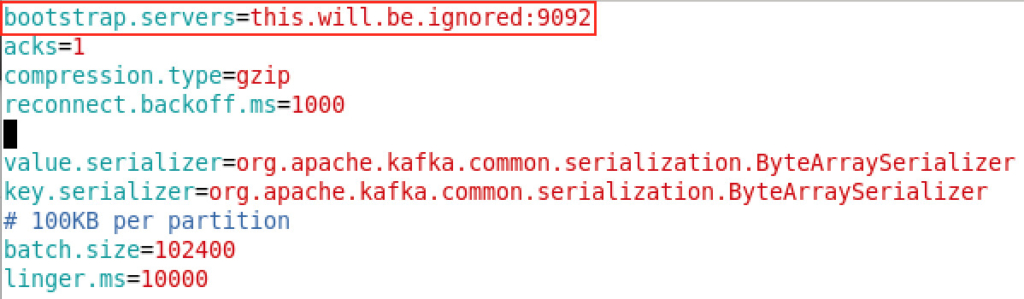
I’ve used, again, the provided template with Oracle GoldenGate installation, the only change I’ve done was to the bootstrap server address. As you may notice, it’s a dummy one. MapR client will take care of handling the connection to MapR’s cluster. And yes, it’s needed to be filled because Oracle’s API is built on commodity Kafka and that’s how commodity Kafka works, but MapR Streams API will take care of the casting.
Let’s jump now into MapR Sandbox and create a new stream. To do that, you need to issue the following command:
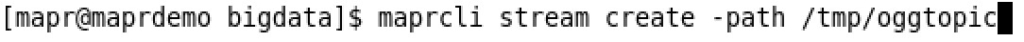
I’ve only provided the namespace for the stream. The topic name, oggtopic, will be created automatically once I start Oracle GoldenGate replicate process. If you scroll up, you’ll notice that it points to this namespace, followed by “oggtopic”.
It’s a good idea to test the stream and the connectivity to MapR Streams server without Oracle GoldenGate first. Refer to this document here for more information on how to do that.
The final step is to start the replication process:
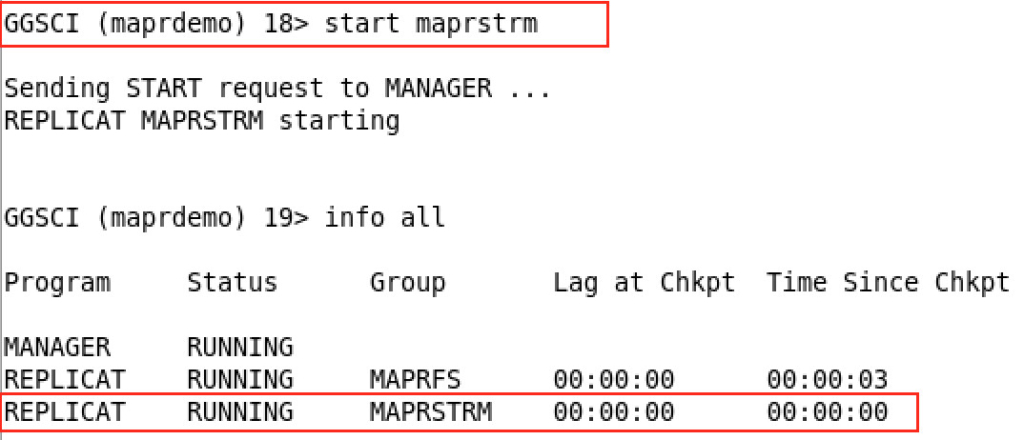
The replicat name is MAPRSTRM. The other one is for another purpose, to stream transactions in MapR-FS. If you’re interested in that, you may want to check this blog here.
I inserted some records in the source to test my configuration, and then checked the target replicat stats:
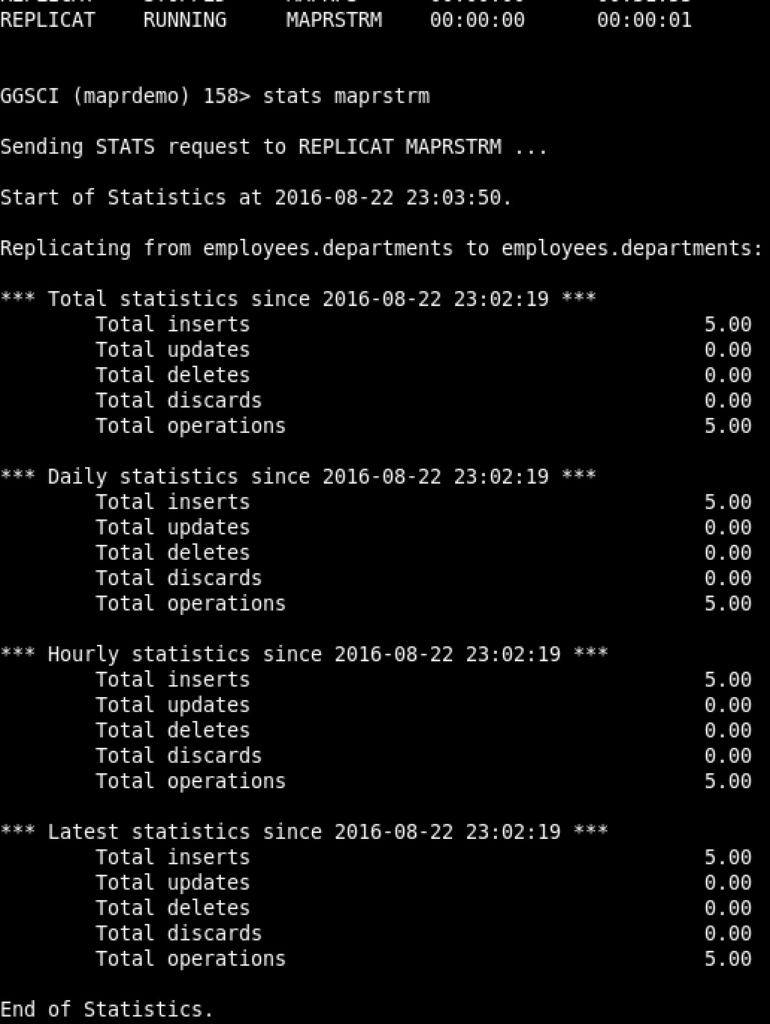
All good! And then on my consumer testing window:

That’s it, as you can see, now any transaction that is committed on the source will be delivered to MapR Stream in real-time.
What’s after that? Well, that’s entirely up to you! Oracle GoldenGate for Big Data helps you to do the integration with MapR Streams, and other frameworks, seamlessly and stream transactional data (inserts, updates, deletes) in real-time. Your MapR Streams can be configured to route it in the right direction; weather that is Spark or else framework.
Conclusion
Oracle GoldenGate for Big Data is a reliable and extensible product for real-time data, transactional level, delivery. From this test, I was able to integrate with MapR Streams (almost) exactly the same way I’d integrated with commodity Apache Kafka.
The possibilities you can do with your real-time streamed data are unlimited, and the value that can be derived from your data is tremendous if used with the proper tools.
Are you on Twitter? Then it’s time to follow me @iHijazi