Streaming data is becoming an essential part of every data integration project nowadays, if not a focus requirement, a second nature. Advantages gained from real-time data streaming are so many. To name a few: real-time analytics and decision making, better resource utilization, data pipelining, facilitation for micro-services and much more.
Python has many modules out there which are used heavily by data engineers and scientist to achieve different goals. While “Scala” is gaining a great deal of attention, Python is still favored by many out there, including myself. Apache Spark has a Python API, PySpark, which exposes the Spark programming model to Python, allowing fellow “pythoners” to make use of Python on the amazingly, highly distributed and scalable Spark framework.
Often, persisting real-time data streams is essential, and ingesting MapR Streams / Kafka data into MapR-DB / HBase is a very common use case. Both, Kafka and HBase are built with two very important goals in mind: scalability and performance. In this blog post I’m going to show you how to integrate both technologies using Python code that runs on Apache Sprak (via PySpark). I’ve already tried to search such combination on the internet with no luck, I found Scala examples but not Python, so here is a fully functional example for you to play with.
Recipe
The following steps reflect my environment. You are free to use other combinations of frameworks, but you need to pay attention to what works with what.
- Spark: I’ve used MapR’s Spark 1.6.1 which runs on top of MapR Converged Platform 5.1.
- Python: Spark 1.6.1 uses Python 2.6 be default, but is compatible with more recent releases of Python, such as 3.4 which I’ve used. I had to manually install it, along with pip 3.4 as well.
- HappyBase Module: “HappyBase is a developer-friendly Python library to interact with Apache HBase. HappyBase is designed for use in standard HBase setups, and offers application developers a Pythonic API to interact with HBase”. I’ve installed version 1.0. Steps are very easy and can be found on HappyBase installation page. *HappyBase itself is licensed under a MIT License. HappyBase contains code originating from HBase sources, licensed under the Apache License (version 2.0).
Preparations
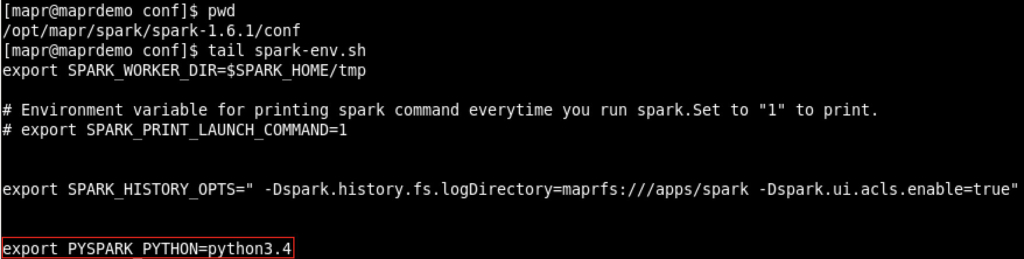
Pointing Spark to Python 3.4
Since I’m going to use Python 3.4 and HappyBase 1.0 (which is complied for Python 3+), I needed to export PYSPARK_PYTHON with the python version I’m going to use. My code works with Python 3+, and will fail with any previous release. So if you are planning to use Python 2, then you need to modify the code accordingly, as well as use another version of HappyBase (probably 0.9).
Creating MapR-DB / HBase Table
I’ve created a table on MapR-DB called ‘clicks’, which will be used to persist the real-time streamed data. Here is the MapR-DB / HBase ‘create’ script along with a sample record:
hbase(main):010:0> create 'clicks','clickinfo','iteminfo' --Sample Record hbase(main):012:0> put 'clicks','click1','clickinfo:studentid','student1' hbase(main):013:0> put 'clicks','click1','clickinfo:url','http://www.google.com' hbase(main):014:0> put 'clicks','click1','clickinfo:time','2014-01-01 12:01:01.0001' hbase(main):015:0> put 'clicks','click1','iteminfo:itemtype','image' hbase(main):016:0> put 'clicks','click1','iteminfo:quantity','1'
Checking MapR-DB / HBase Table
And here is how the table looks like now, showing only the one record we inserted previously:

Create MapR Streams / Kafka Topic
Since I’m going to use MapR Streams as a streaming platform, I created a path and topic accordingly. You’d do the same with commodity Apache Kafka, with slight difference with the commands used:


PySpark Code
This is the most important, and exciting part. Since this is Python code, I strongly believe that it’s self-explanatory. But in general, here is the code logic:
- Importing Python needed modules.
- Initializing Spark job parameters (i.e. lifespan of the application is 30 seconds, pulling messages every 10 seconds, etc..).
- Creating SparkContext and StreamingContext.
- Defining a function which will be called to run the application main streaming thread.
- Printing some application related details.
- Defining the MapR-DB / HBase connection details and MapR-Streams / Kafka connection details.
- Defining a function which will be called to save RDDs into MapR-DB / HBase.
- Creating MapR Streams / Kafka DStream.
- Filtering the stream, splitting, filtering and mapping.
- Passing each RDD into the function we defined earlier (point #7).
- Run the streaming thread.
You may view (pretty code) and download the py file from here.
#==================================================
# Kafka-MapR-DB-HBase.py
# Spark Python Script Kafka / MapR Streams => HBase
#==================================================
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import *;
from pyspark_ext import *
import happybase
#==================================================
# Initialization / Control
#==================================================
appName = "Kafka_MapR-Streams_to_HBase"
config = SparkConf().setAppName(appName)
props = []
props.append(("spark.rememberDuration", "10"))
props.append(("spark.batchDuration", "10"))
props.append(("spark.eventLog.enabled", "true"))
props.append(("spark.streaming.timeout", "30"))
props.append(("spark.ui.enabled", "true"))
config = config.setAll(props)
sc = SparkContext(conf=config)
ssc = StreamingContext(sc, int(config.get("spark.batchDuration")))
#==================================================
# Main application execution function
#==================================================
def runApplication(ssc, config):
ssc.start()
if config.get("spark.streaming.timeout") == '':
ssc.awaitTermination()
else:
stopped = ssc.awaitTerminationOrTimeout(int(config.get("spark.streaming.timeout")))
if not stopped :
print("Stopping streaming context after timeout...")
ssc.stop(True)
print("Streaming context stopped.")
#==================================================
# Output application details
#==================================================
print
print ( "APPNAME:" + config.get( "spark.app.name" ))
print ( "APPID:" + sc.applicationId)
print ( "VERSION:" + sc.version)
print
#==================================================
# Begin of Mapping Logic
#==================================================
hbase_table = 'clicks'
hconn = happybase.Connection('maprdemo')
ctable = hconn.table(hbase_table)
topic = ["/users-stream:clicks"]
k_params = {"key.deserializer" : "org.apache.kafka.common.serialization.StringDeserializer" \
,"value.deserializer" : "org.apache.kafka.common.serialization.StringDeserializer" \
#,"zookeeper.connect" : "maprdemo:5181"
#,"metadata.broker.list" : "this.will.be.ignored:9092"
,"session.timeout.ms" : "45"
,"group.id" : "Kafka_MapR-Streams_to_HBase"}
def SaveToHBase(rdd):
print("=====Pull from Stream=====")
if not rdd.isEmpty():
print("=some records=")
for line in rdd.collect():
ctable.put(('click' + line.serial_id), { \
b'clickinfo:studentid': (line.studentid), \
b'clickinfo:url': (line.url), \
b'clickinfo:time': (line.time), \
b'iteminfo:itemtype': (line.itemtype), \
b'iteminfo:quantity': (line.quantity)})
kds = KafkaUtils.createDirectStream(ssc, topic, k_params, fromOffsets=None)
parsed = kds.filter(lambda x: x != None and len(x) > 0 )
parsed = parsed.map(lambda x: x[1])
parsed = parsed.map(lambda rec: rec.split(","))
parsed = parsed.filter(lambda x: x != None and len(x) == 6 )
parsed = parsed.map(lambda data:Row(serial_id=getValue(str,data[0]), \
studentid=getValue(str,data[1]), \
url=getValue(str,data[2]), \
time=getValue(str,data[3]), \
itemtype=getValue(str,data[4]), \
quantity=getValue(str,data[5])))
parsed.foreachRDD(SaveToHBase)
#===================================================
# Start application
#===================================================
runApplication(ssc, config)
print
print ("SUCCESS")
print
Execution
Spark Submit Command
You may run this code on PySpark, without Spark master, if you wish to test/debug your code. The following command bypass that and submit it directly to Spark master.
./spark-submit --master yarn-client \ --py-files ~/kafka-mapr-db-hbase/pyspark_ext.py \ --deploy-mode client --executor-memory 1G --verbose --driver-memory 512M \ --executor-cores 1 --driver-cores 1 --num-executors 2 --queue default \ ~/kafka-mapr-db-hbase/Kafka-MapR-DB-HBase.py
Producer
To simulate the real-time data stream, I’ve created a Kafka console producer and produced some messages that represent “clicks” by different users:

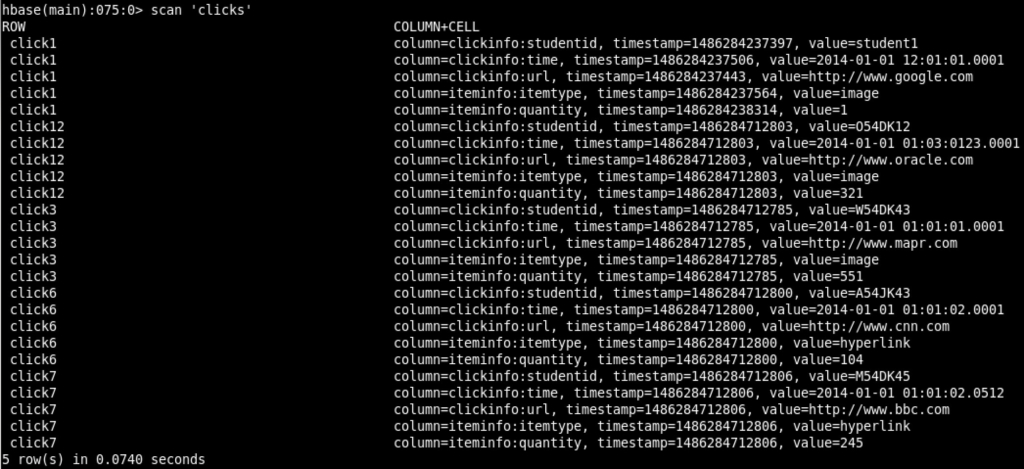
MapR-DB / HBase Table After
And here is how the MapR-DB / HBase looks like after inserting the previous 4 rows:
That’s it!
If you have any questions, please leave a comment. If you wish to download the .py code file, click here.