Real-Time Kafka / MapR Streams Data Ingestion into HBase / MapR-DB via PySpark
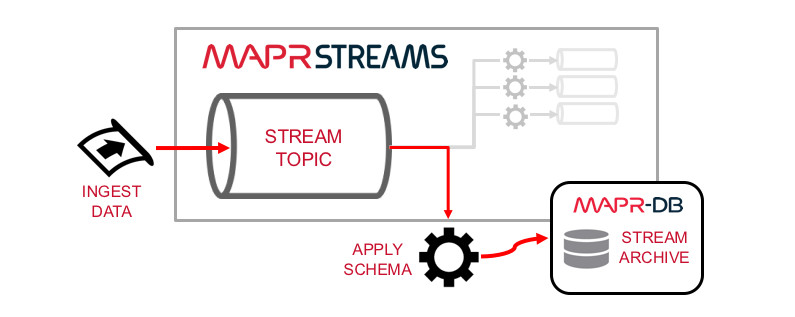
Streaming data is becoming an essential part of every data integration project nowadays, if not a focus requirement, a second nature. Advantages gained from real-time data streaming are so many. To name a few: real-time analytics and decision making, better resource utilization, data pipelining, facilitation for micro-services and much more. Python has many modules out […]
Perfecting Lambda Architecture with Oracle Data Integrator (and Kafka / MapR Streams)
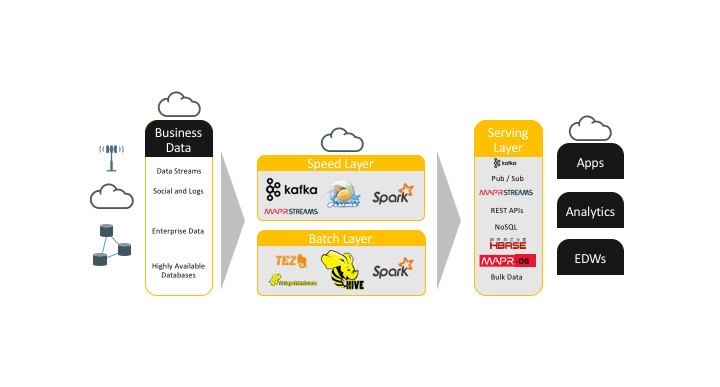
Republished by: MapR Technologies Datafloq ——- Introduction “Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch– and stream-processing methods. This approach to architecture attempts to balance latency, throughput, and fault-tolerance by using batch processing to provide comprehensive and accurate views of batch data, while simultaneously using real-time stream processing to provide views of online […]