The term “unstructured data” is being extensively used nowadays when speaking of subjects related to big data and data analytics. Some people describe it as data that typically cannot fit in a relational database, others describe it as data that cannot be easily processed using conventional methods and tools. Both descriptions are correct. I’m not talking here about JSON, or XML, Social-Media/Twitter data (which essentially can be retrieved as JSON) or even BINARY data files. These do have some structure to them, and I would classify them under the semi-structured data category. What I’m talking about here is video, audio and image files kind of unstructured data.
I like to call these kinds of data “unstructured information”. Video, image and audio files can contain numbers, dates and facts that can be easily recognized by humans using essential senses such as sight and hearing. Think of a simple portrait image of person X, it can tell us few things such as: person’s name (if known to the person looking at it), average age, gender and emotion among other things.
Merrill Lynch, an American investing and wealth management division under the auspices of Bank of America, cited a rule of thumb that somewhere “around 80-90% of all potentially usable business information may originate in unstructured form”, and that estimate was in 1998. There relies a tremendous, yet untapped, potential that can translate into profit, efficiency and extreme risk/threat management.
With the proper way of storing, retrieving and analyzing these unstructured assets, organizations can harvest a great deal of tangible information and execute actions based on them, or better yet prevent something from happening.
NOW IS THE TIME TO GET INVOLVED
With the new advancements in computing power and storage capabilities, we’re able now to use artificial intelligence (AI) and machine learning (ML) techniques that we only dreamed of a couple of decades ago. By leveraging algorithms and deep learning techniques, we can process a huge amount of unstructured data (and structured/semi-structured) that no human can possibly process on his own, or with the same level of efficiency, not even a close-one, to extract valuable information.
What’s more, is the pace these AI/ML algorithms are spreading at in many frameworks. The usage of AI and ML are not locked down, anymore, to organizations with huge spending budgets, or even extensive skill-sets and expertise. There are a bunch of open-sourced libraries out there to get anyone up and running with very basic knowledge in these areas; and it will only get better, easier and faster over time.
I’m not simplifying the problem of processing unstructured data, I’m saying it’s now more doable than it was 1-2 decades ago. With the right knowledge, techniques and tools you can get in the game, and you should if you want to stay in the race.
RECOGNIZING FACES IN VIDEO FILES WITH PENTAHO
In this blog, I want to share with you a small prototype that I’ve built to recognize individuals’ faces in video files. In the beginning of this blog, I highlighted that I like to refer to these assets (videos, images, etc..) as “unstructured information”. I’ll show you how I was able to capture information from video files by using Pentaho (a Hitachi Vantara‘s big data, analytics and IoT platform) which helped in capturing, processing (with deep learning models) and aggregating the data into actionable insights.
In this prototype, I’ve created two simple transformations. The first transformation does the following in high level:
- Get/retrieve images from a specific location
- Extract details/metadata from each image
- Build encodings

The images are basically photos taken from my personal phone of myself and a couple of colleagues at work, among others from the internet. The location of the images is on my local file system, but in real world it could be anything such as S3, Hitachi Content Platform (HCP), FTP, webservice, HDFS, GCS or virtually anywhere. The transformation retrieves these images and start processing each image file to extract details such as unique ID and name of the person. I’ve built the metadata of the images in such way to use these as identifying parameters later on, but in reality (actual production environments) the logic can be different.
The “Build Encodings” piece in the transformation (last step) does three things mainly:
- Quantify human faces in an image (not recognize).
- Build encoding for each identified face using Python face_recognition and cv2 free (open-source) libraries.
- Serialize the results and store them in a “pickle” file
What I’m doing here first is quantifying the faces in my dataset (images). We are not training a network here, it has already been trained to create 128-d embeddings on a dataset of ~3 million images (thanks to the folks at dlib project). So I’m simply using this pre-trained network to construct 128-d embeddings for each of the images in my dataset.
For the classification of each face, I’ve used a simple k-NN model + votes to make the final face classification (you can use other ML models if you want). The detection method I used was CNN. You may use HOG if you want better performance, but CNN generally is more accurate (but comes with a cost of being slower).
The result of this transformation is a picke file which simply contains a list of encodings for each face, and their ID/Name.
The second transformation is where the fun starts (at least for me). Here is what it does in high level:
- Get list of videos
- Have the videos processed frame by frame, quantify faces and recognize who is the person.
- Produce output data containing information such as person ID, name and at which second he/she appeared exactly.
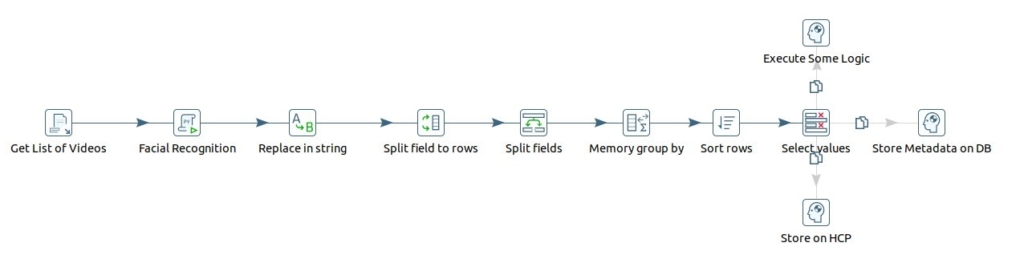
In my prototype, I used a simple 6 seconds video file I took using my phone camera, which has two of my colleagues in the office. The video file is stored on my local file-system, but (again) in reality, it could be anywhere like Hitachi Content Platform (HCP), S3, GCS, HDFS or else. Then for recognizing the faces, I used the encodings (pickle file) I created in the previous transformation and again applied face_recognition and cv2 libraries to quantify faces, recognize the faces (using HOG as detection method this time for faster processing, as I processed frame by frame) and eventually produce facts.

Here is an example of the input video file that I’ve used in my prototype. Click on the image on the right to have a look, it’s only 6 seconds. Notice that it has no labels on the faces, it’s a raw unstructured information/data.

Now once I execute my transformation, a new video file is produced which marks the quantified faces and label/tag them in real-time. Click on the image to the left to see how that looks like, it’s also 6 seconds.
The generated video file with labels/tags is then saved to my local file system. As you could see, the generated video file itself has usable information that can help anyone identify the individuals easily. What’s more valuable is the generated information in form of structured data that can be used to build intelligence in many ways (i.e dashboards). The following table was also a result of the transformation I created, and it contains information of each recognized face, such as the person ID, name and the time timestamp his face appeared in the video among other information such as the original video file path/name, its size, extension and the newly produced file which has live labels/tags on the faces.

WHAT’S NEXT?
Using the information derived from the previous process, we can use the output data in many applications. One could be to identify if specific person was on the video or not, another would identifying at which minute exactly a specific person appeared. That could be be for surveillance/security use-cases, innovative marketing/customer experience and many others.
In my simple prototype I was saving all the outputs (videos, information, etc..) to my local file-system, but in reality you can save the results to some analytical databases or better yet a holistic solution such as Hitachi Content Intelligence (HCI) which is capable of connecting and indexing data that resides on Hitachi Content Platform (HCP) and other repositories and then making it easy for you to locate and identify the most relevant data regardless of its type or location, enhance data value with automated cataloging, transformation and augmentation and facilitating the access to relevant data with richer context available where and when you need it.

Lastly, it’s worth mentioning that using deep learning techniques like the ones I’ve used here are highly CPU intensive. The usage of GPU substantially accelerates the processing, because simply many of the deep learning frameworks are enhanced for GPUs. Hitachi Vantara provides advanced servers with GPUs that are specifically designed for advanced analytics, artificial intelligence and deep learning applications.
CONCLUSION
At Hitachi Vantara, we call it the data stairway to value. Climbing that stairway starts with acquiring, storing, managing and protecting the data, followed by enriching, classifying and cataloging it, followed by discovering, integrating and fully orchestrating the process in order to monetize the value.
In this blog, I mainly focused on one aspect where Pentaho can help in solving a buzzword that is highly used nowadays, unstructured data, but not many has actually put it to work or struggle with it. Pentaho is big data, analytics and IoT platform that helps organization in managing data pipelines, end-to-end, with ease, efficiency and reliability. All the way from data acquisition, to data engineering, to advance analytics and visualization.