The metadata of IBM’s integration stack that is. If you have been following my previous posts “Harvesting the Cloud“, “Big Data & OEMM” and others, you’d know that I tend to experiment and prove OEMM capabilities to harvest ANY metadata provider. In this experiment, I’ll be harvesting IBM’s integration stack using native bridges shipped with Oracle Enterprise Metadata Management.
This post aims to show the native ability of OEMM to harvest IBM’s integration stack. Like other experiments I’ve done before, this one is more of “what can be done” rather than “how it can be done”. The “how” is complicated with IBM’s integration solutions, but that’s the pain I have fully chosen to go through to come up with the amazing results you are about to see.
Ingredients
My Oracle Linux 7 Machine (which I’ve just upgraded its resources to handle IBM’s Information Management services)
Oracle VirtualBox
My Customized OEMM VM, running OEMM version 12.1.3.0.1.
IBM VMs with many components to have their products function, I’ll only list the main ones plus the ones I harvested with OEMM:
InfoSphere Server
Information Server Services
IBM DB2 9.7.0.441 (harvested)
IBM DataStage 8.7 (harvested)
IBM Cognos 10.2 (harvested)
IBM Data Architect 8.1.0 (harvested)
Scenario
In this experiment, I used some tables in IBM DB2 OLTP database (as a source) that are being extracted by IBM DataStage (with some joins and aggregations) and eventually loaded into an IBM DB2 data warehouse. On top of the data warehouse, I used IBM Cognos to build some reports and dashboard.
The flow of data would be:
IBM DB2 (transactional) => IBM DataStage => IBM DB2 (warehouse) => Cognos
Simple, huh? While it does sound easy, building it wasn’t. I won’t lie though, I do have good experience with IBM’s integration portfolio.
The Execution
Installing, configuring and using IBM’s products is out of scope for this post. I’ll only show you high level screenshots of the preparation part for the integration to understand the scenario better, and feel the authenticity of the experiment.
Step 1
Creating tables in IBM DB2 OLTP and DWH databases using IBM Data Architect: Once I was done, I executed the DDL on the IBM DB2 database. The OLTP database name is JKLW_DB, and the data warehouse is JKLW_DWH.
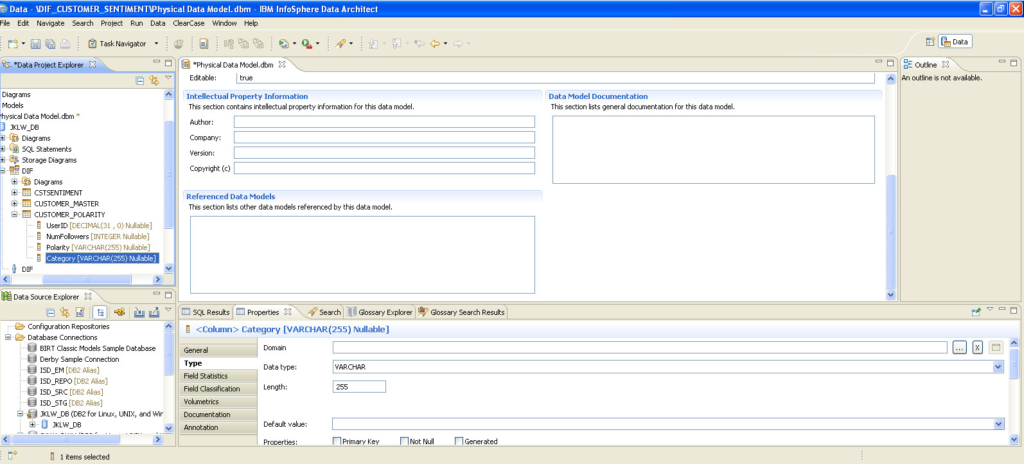
Step 2
After creating the tables I need (source and target) for my ETL jobs and reporting after, I was ready to design/modify my IBM DataStage jobs. The jobs will load data into the OLTP from flat files, then some other jobs will populate the DWH with some lookups and aggregations.
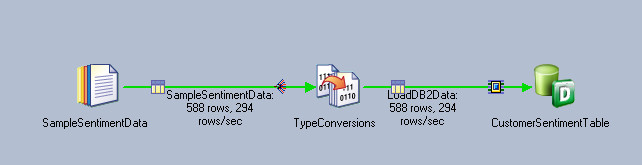
Here is a screenshot of the job design which extract data from flat file and load it into a DB2 table:
Here I’m populating my DWH, to make it a bit challenging I added some lookup and aggregation:
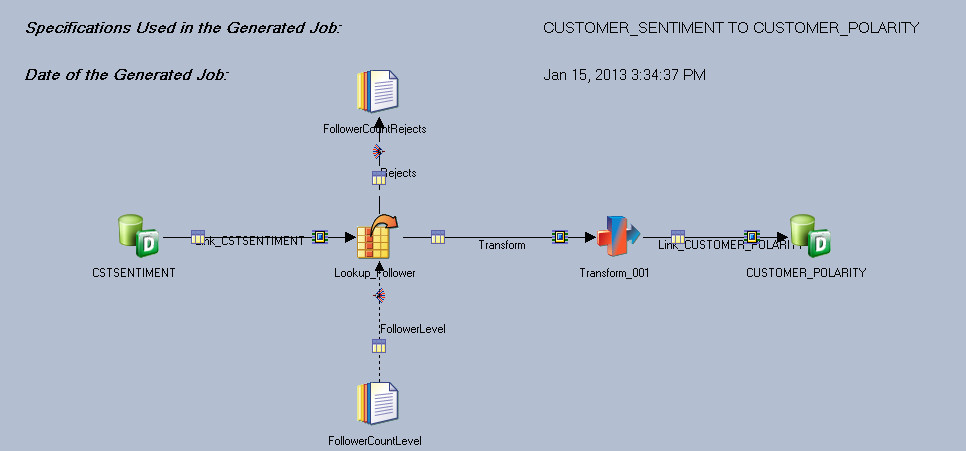
Once I was done, I ran the jobs and all tables were been populated successfully.
Step 3
This one was a bit tricky for me since I personally don’t like working with reporting applications (design reports, dimensions, etc..), but I’ve managed to have it done:
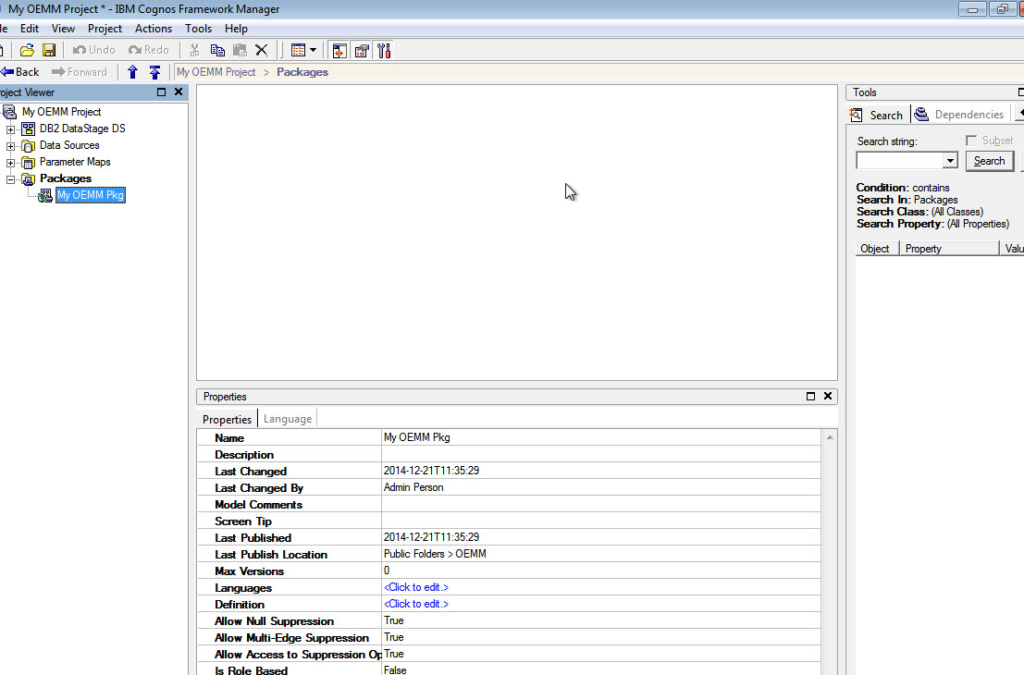
Here I created a new project in Cognos using Framework Manager, added the needed connections and published the package:
Following that, I jumped into Cognos to create some reports and dashboard. Nothing fancy but serves the purpose.:
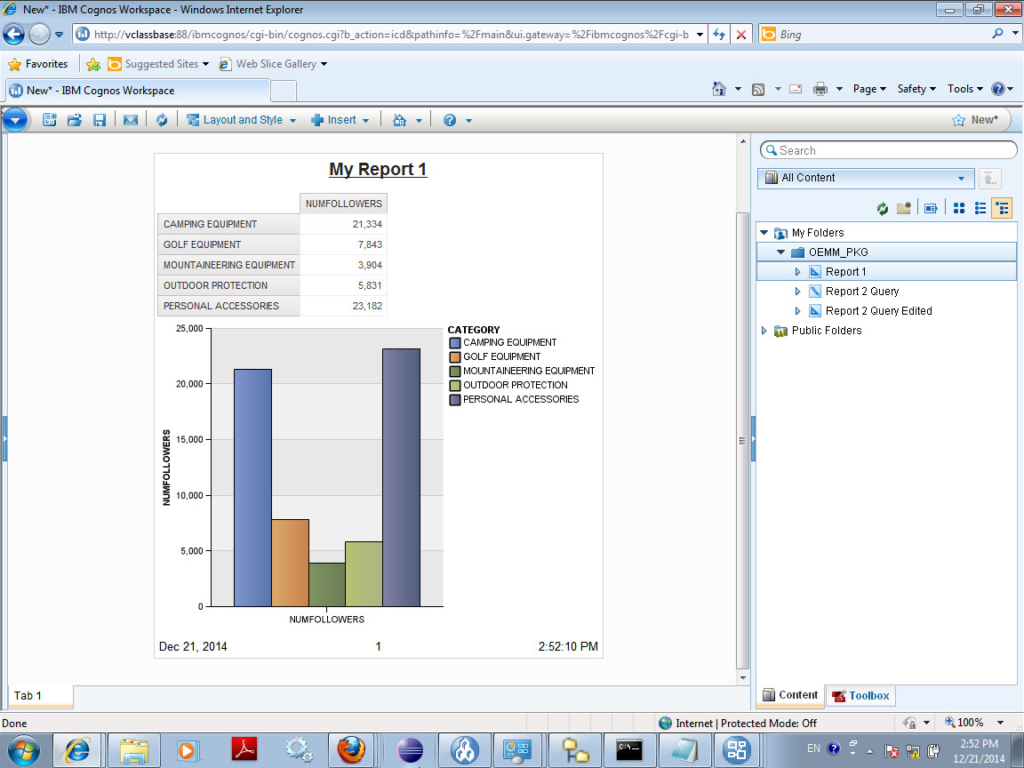
And the dashboard (workspace) looked something like this:
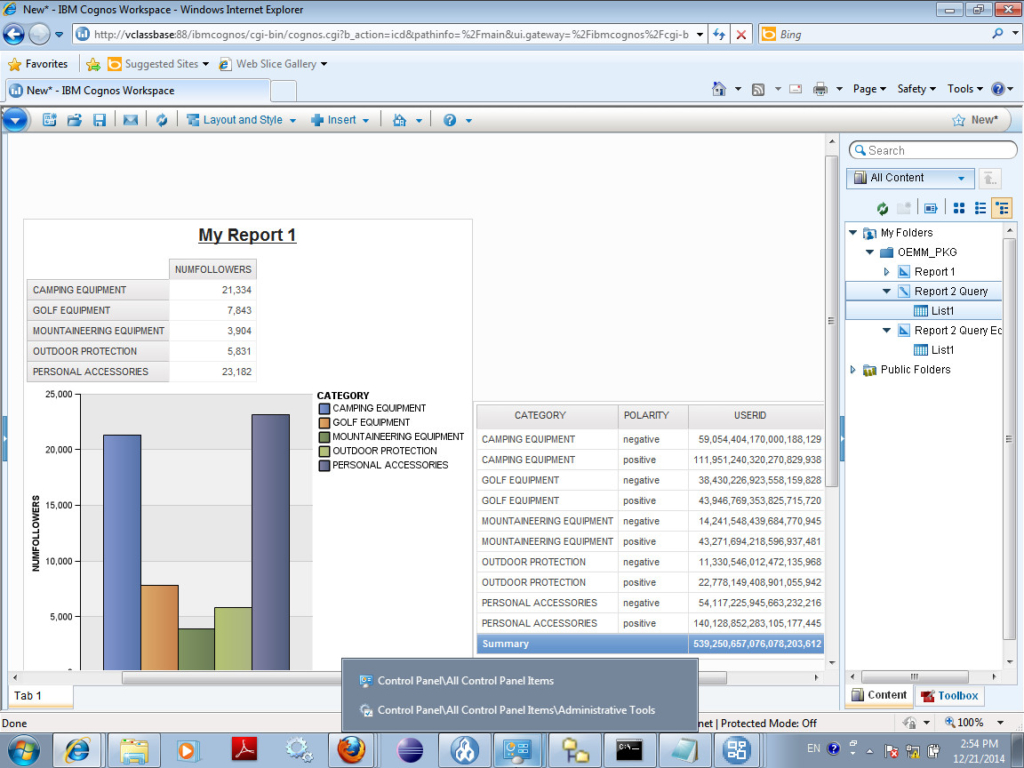
Saved everything and was ready to roll into OEMM.
Step 4 (A)
First of all, I needed to create models and harvest them for all of the preceding sources. I started with IBM DB2 (the OLTP database), the configuration was:
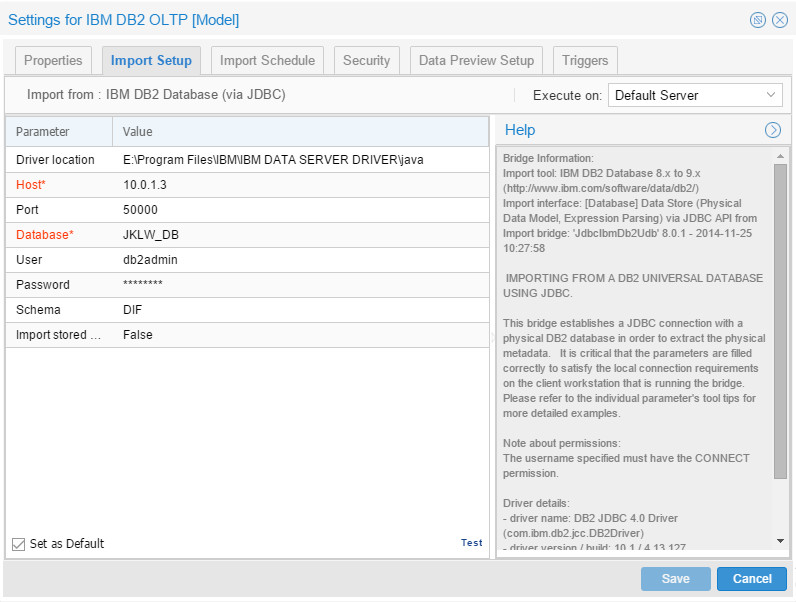
Resulted in:
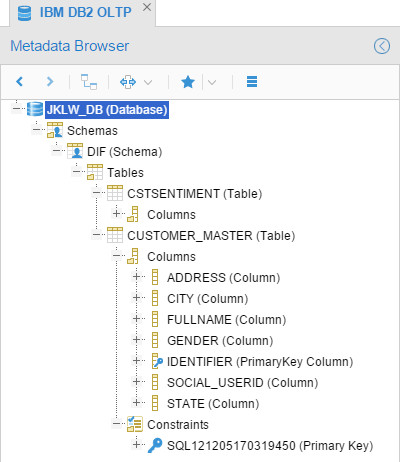
Then I’ve created a model for the IBM DB2 DWH, the configuration was:
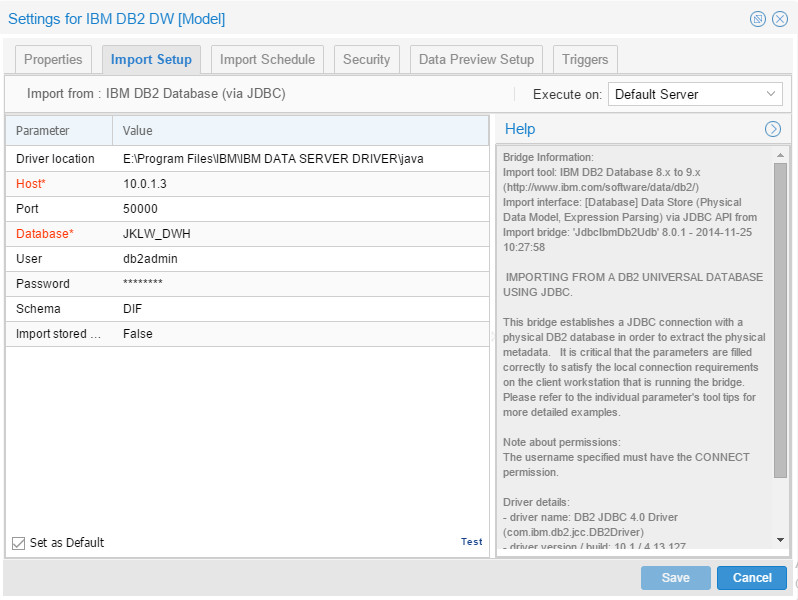
Resulted in:
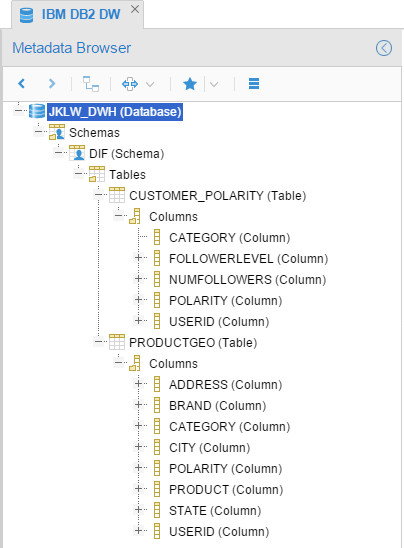
Then I created a model for IBM Data Architect (just for fun), the configuration was:
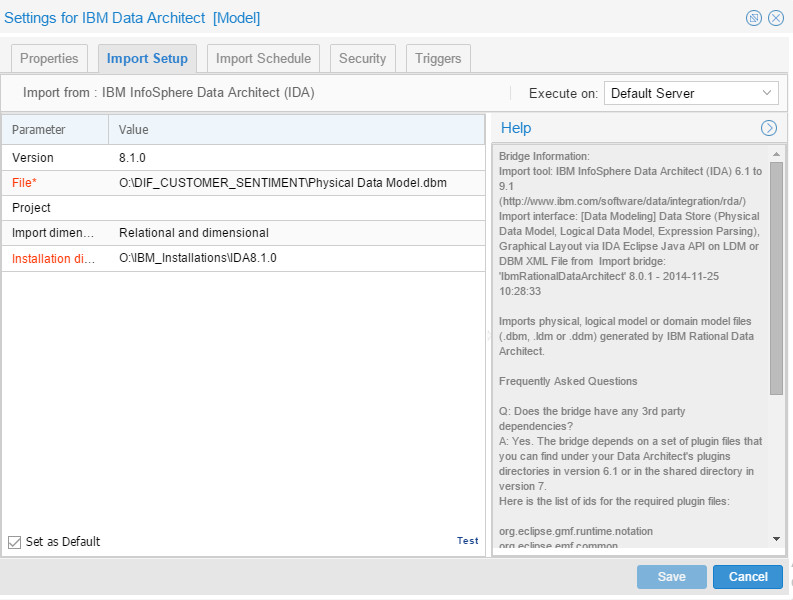
Resulted in:
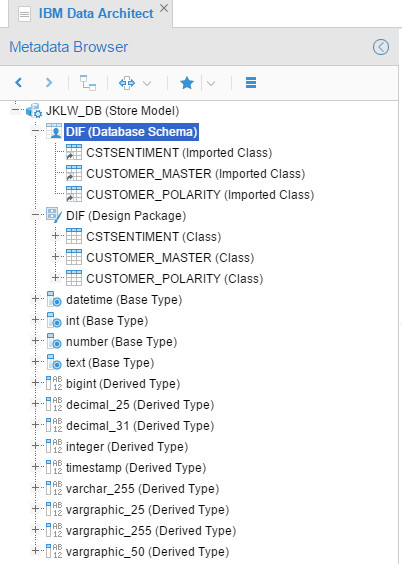
Then I created a model for IBM DataStage. Configuration was pretty straightforward, I only exported the project in DataStage and pointed OEMM to the file:
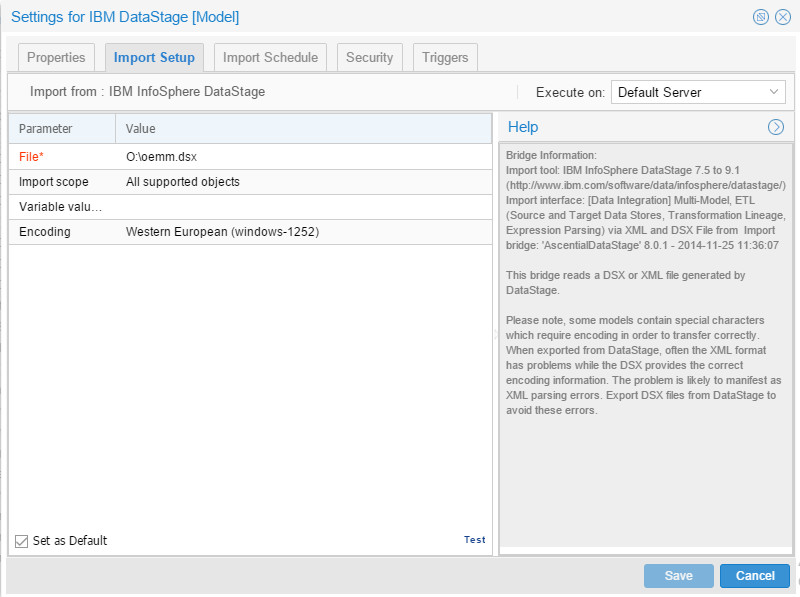
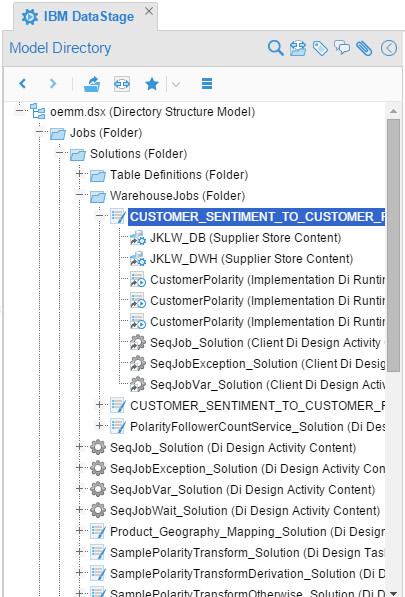
Resulted in:
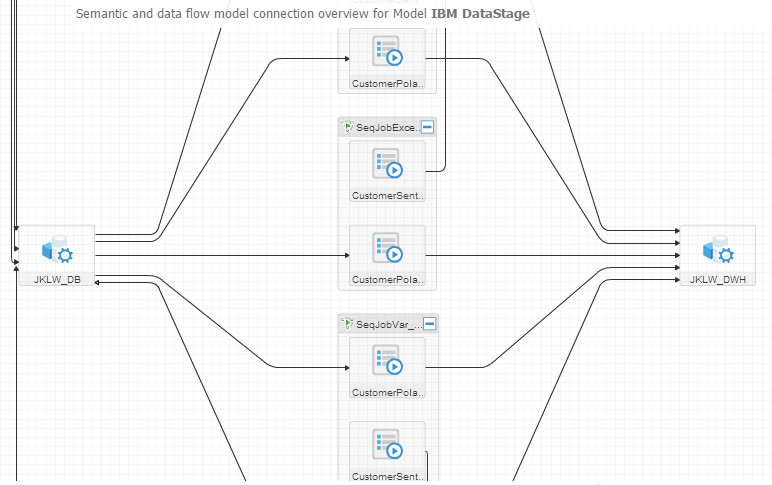
And when I clicked on the Semantic and data flow overview I got (this is a zoomed-in version):
The final model to harvest was the Cognos, the configuration was:
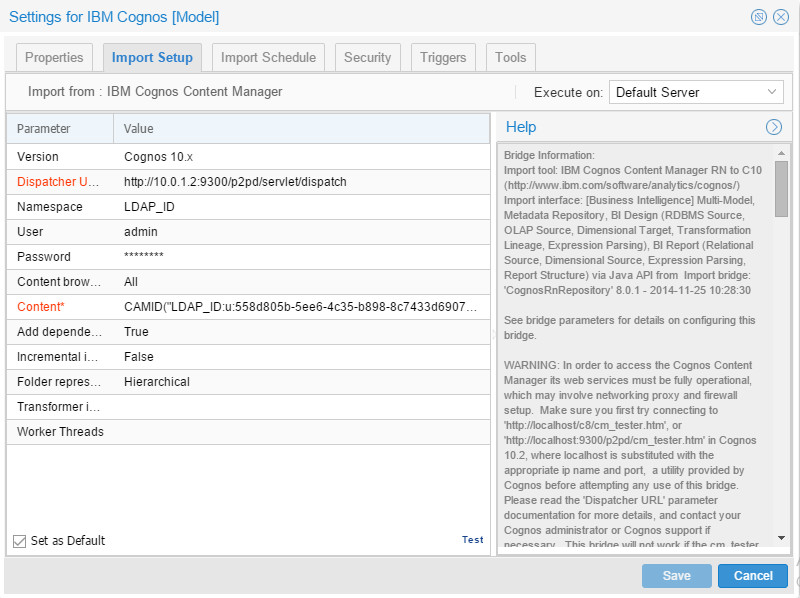
And the result was:
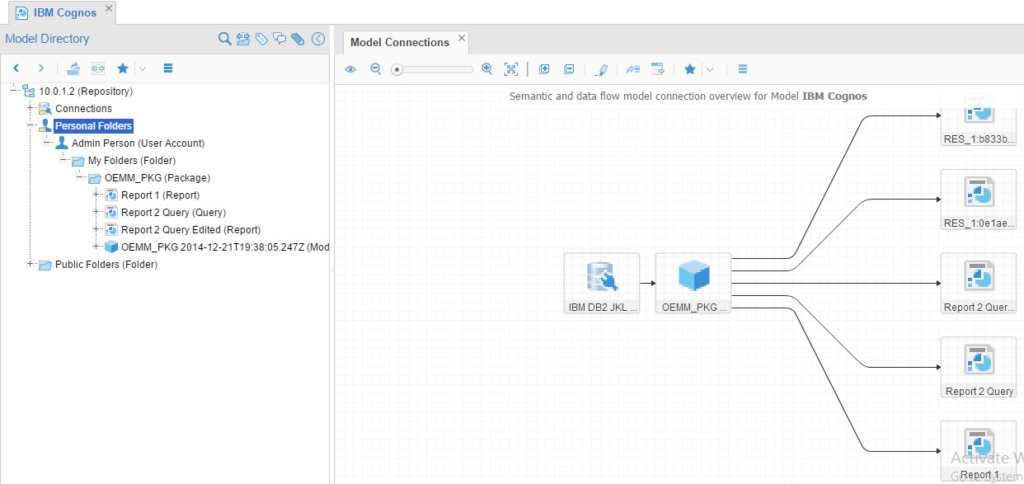
Step 4 (B)
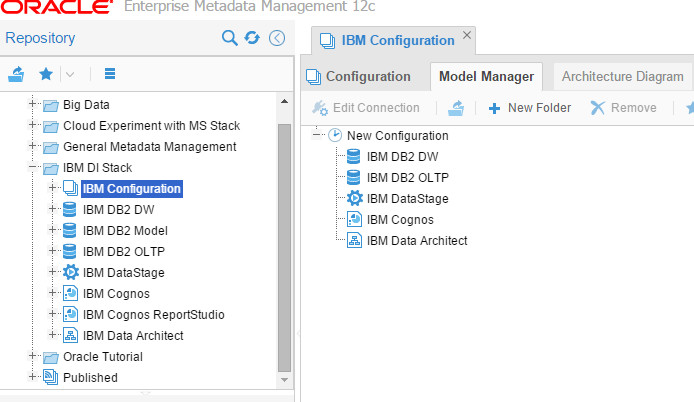
The stitching step, my favorite. So I’ve created an empty configuration and dropped all the models I’ve created, then validated (stitched) them:
The result for Architecture Diagram was:
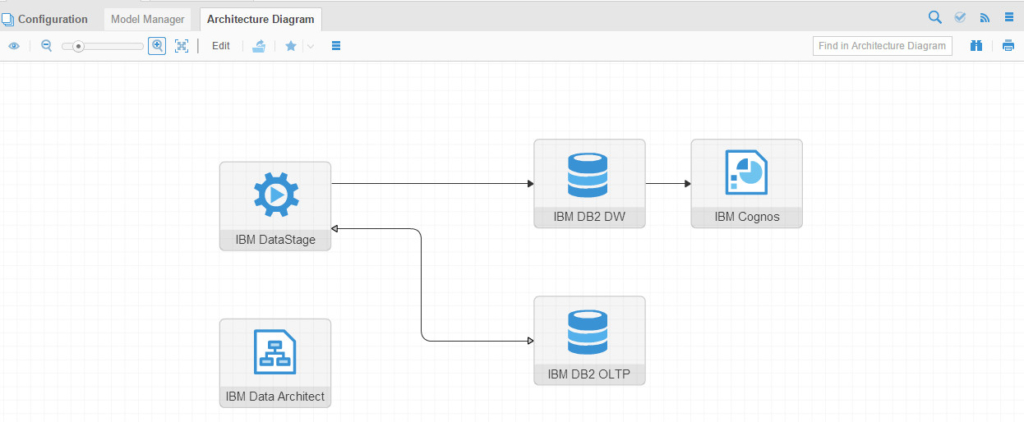
Notice the flow: IBM DB2 OLTP reading/writing from/to IBM DataStage, then IBM DataStage loading into IBM DB2 DWH and eventually IBM Cognos is showing reports based on the DWH data.
Let’s open the IBM Cognos node and see its semantic flow:
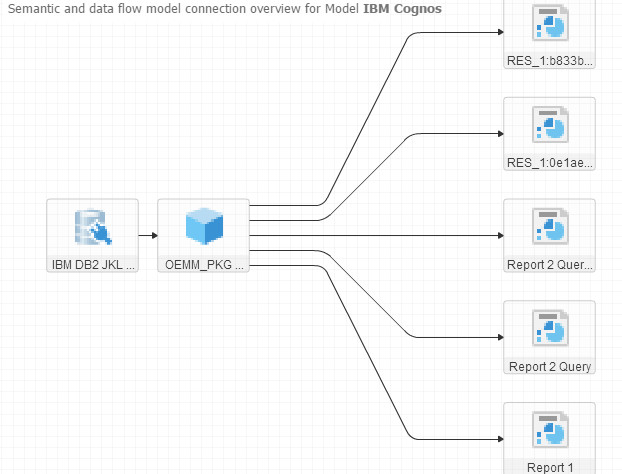
And if you dig a little deeper (say into Report 2 Query), you’ll get:
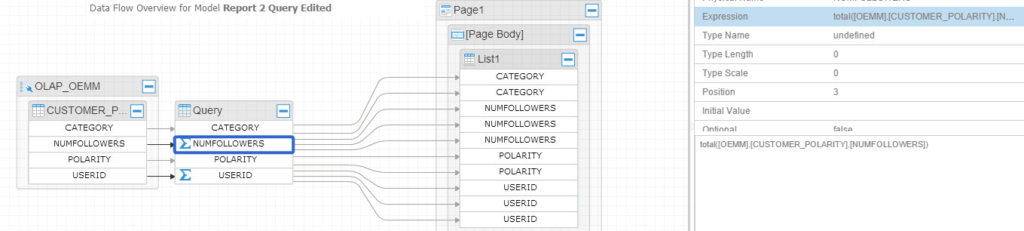
I’ve selected the “NUMFOLLOWERS” column to show you the underneath function behind it. Here is another flow example for Report 1, having the chart and crosstab:
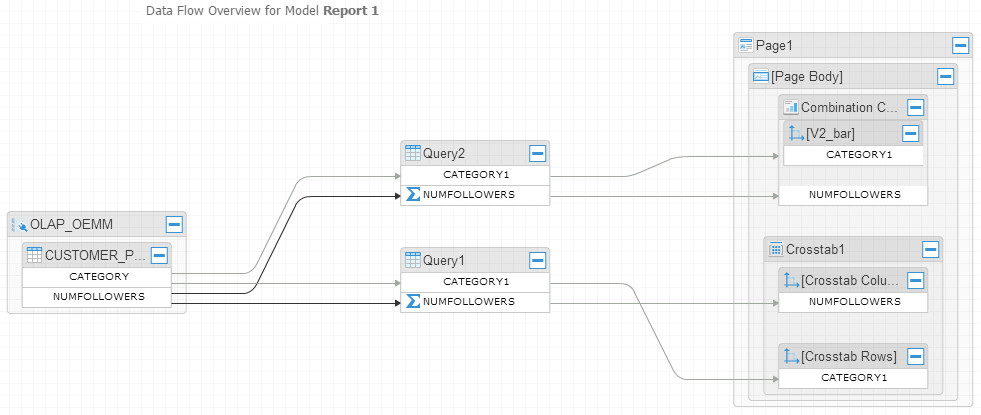
Pretty, isn’t it? What I can do now is limitless, let’s try to run some data lineage from the report I created in Cognos. There is a chart if you remember in “Report 1”, and I wanted to know the full lineage of data for that chart:
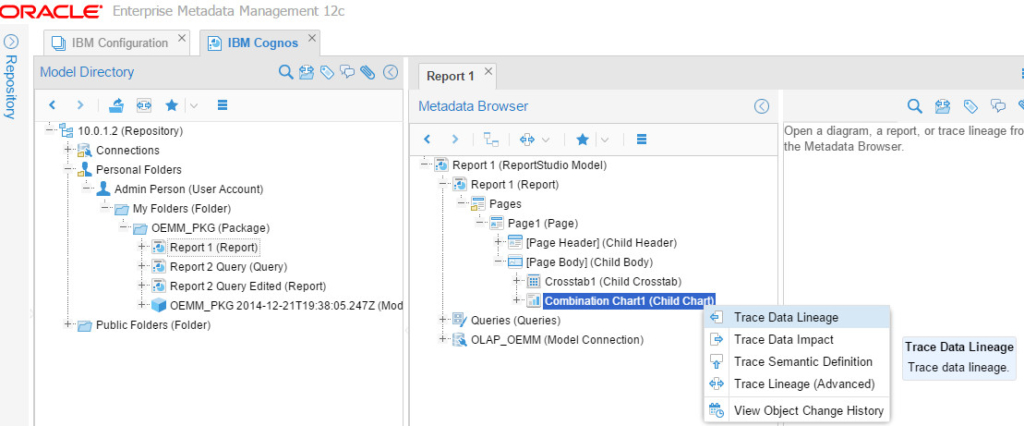
And I got the following incredible flow:
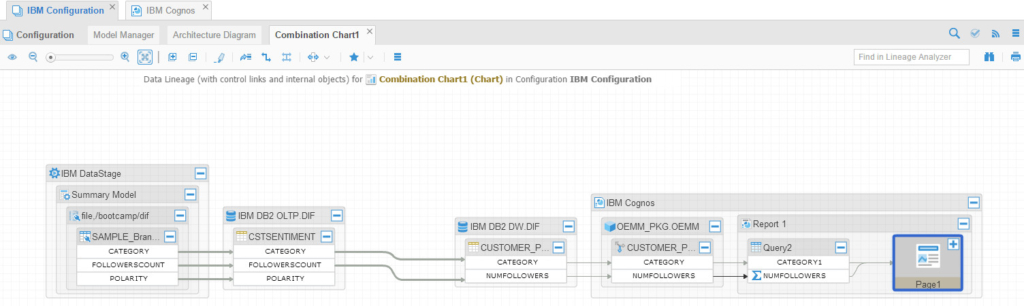
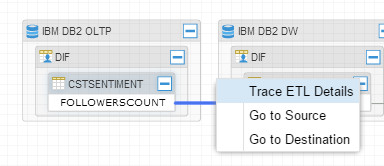
Here we have DataStage loading flat file in the DB2 OLTP database, then there is DataStage job loading into the DWH and finally Cognos is reading data from the DWH. If you want to dig deeper in the ETL process between the OLTP and DWH, simply right click on any arrow connecting from the OLTP to the DWH and select “Trace ETL Details”:

Doing that showed me the following detailed trace (I zoomed in to make it more clear for you to see the join condition):
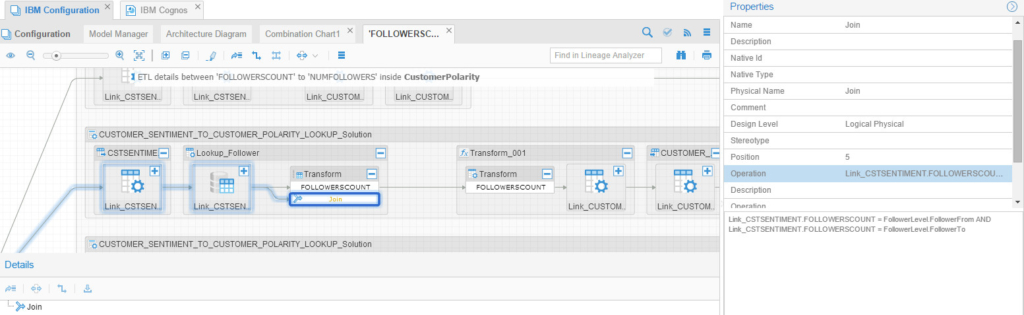
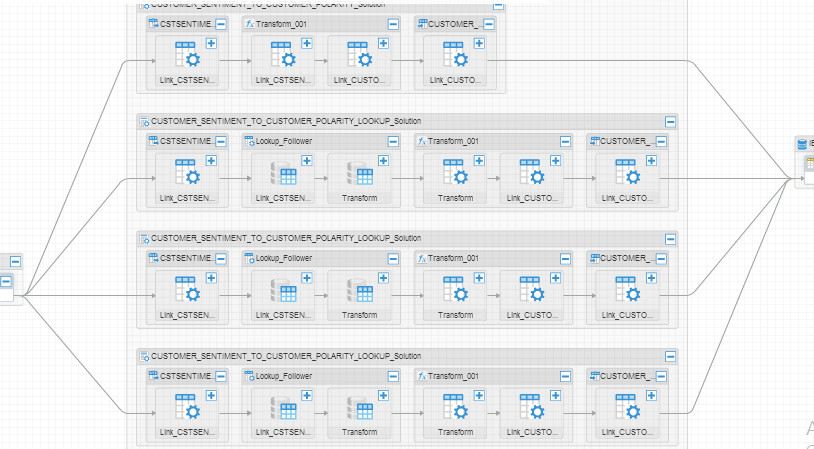
This is how it looked before I zoomed in and expanded the transformation node, you’ll see more than one DataStage job here because there is more than one DataStage job feeding the target and could be via any of them:
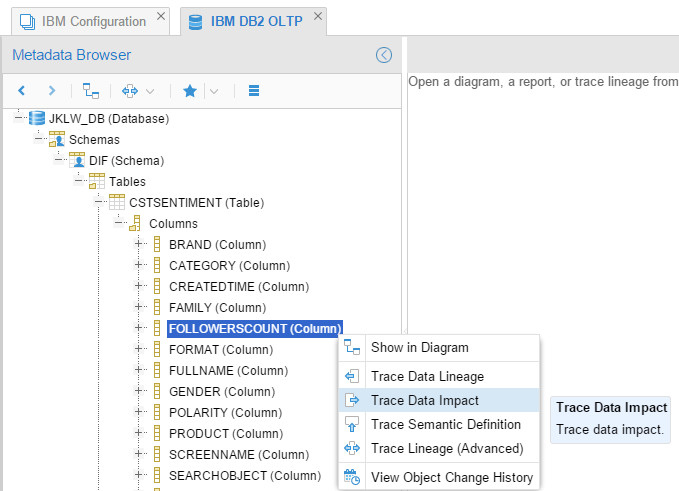
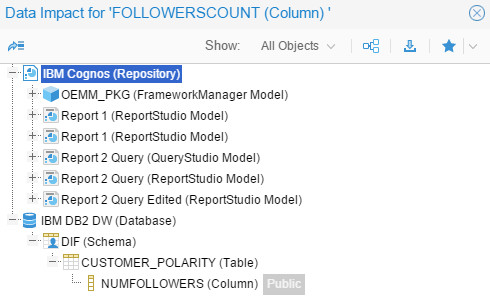
What about some impact trace and analysis? Hmm, that’d be interesting. I ran a trace on the column “FOLLOWERSCOUNT” in the IBM DB2 OLTP database:
I’ve chosen “Text/List” rather than “Graph/Flow” this time:
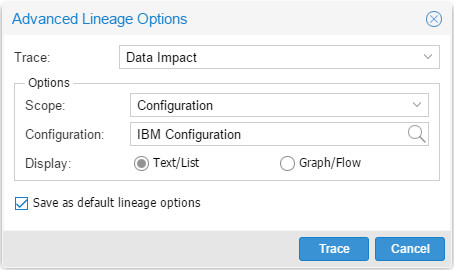
And I got every single object that’d be impacted in a convenient tree view:
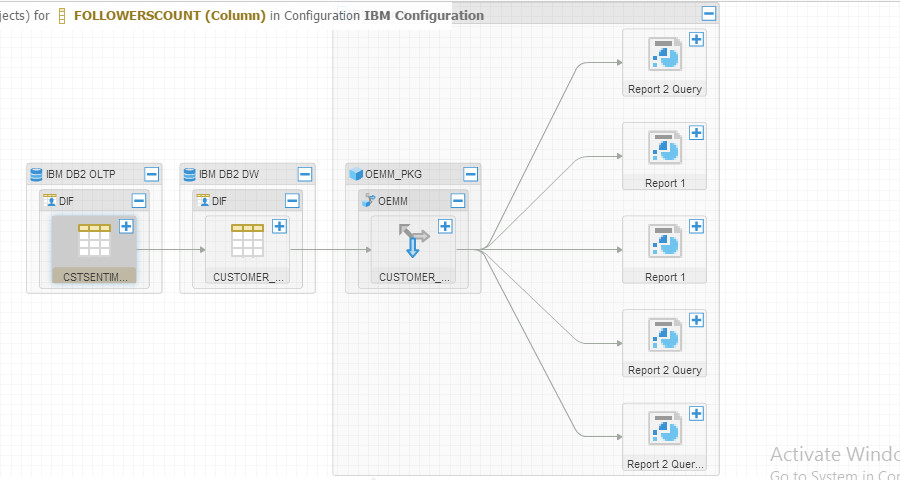
Then I wanted to see that in a flow:
You can always trace the ETL details with OEMM:
Step 4 (C)
Last thing I wanted to test is the ability to populate a business glossary. OEMM can virtually populate a business glossary from any model you harvested. I wanted to a business glossary for IBM Data Architect:
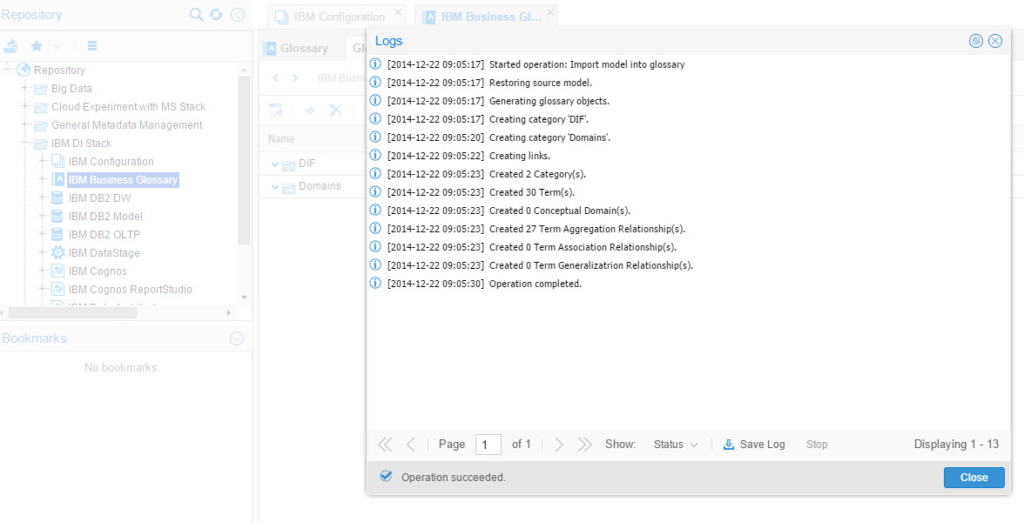
Then I injected the populated business glossary into my “BM Configuration” inside OEMM and validated (stitched) it. That resulted in the following Architecture Diagram:
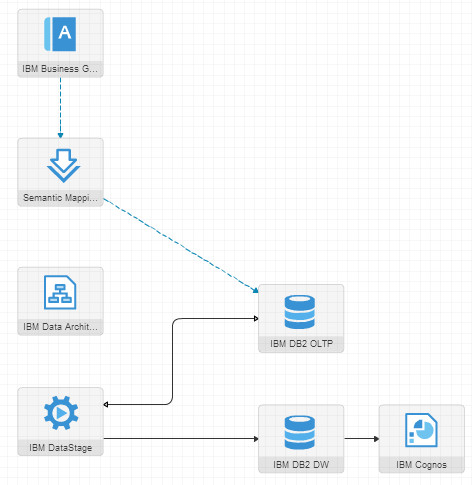
Notice that now the glossary is stitched with the actual OLTP database, which honestly was beyond my personal expectations, I thought it’d just stitch IBM Data Architect. Then I traced the semantic usage for one of the terms in the business glossary:
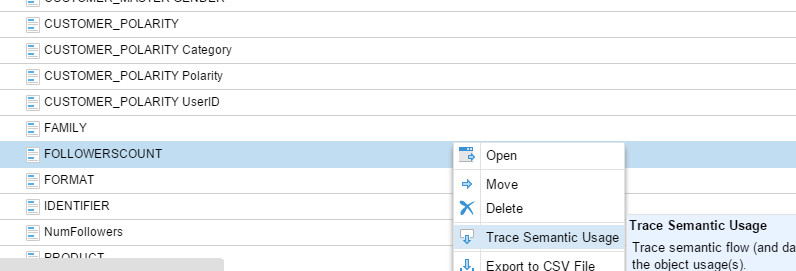
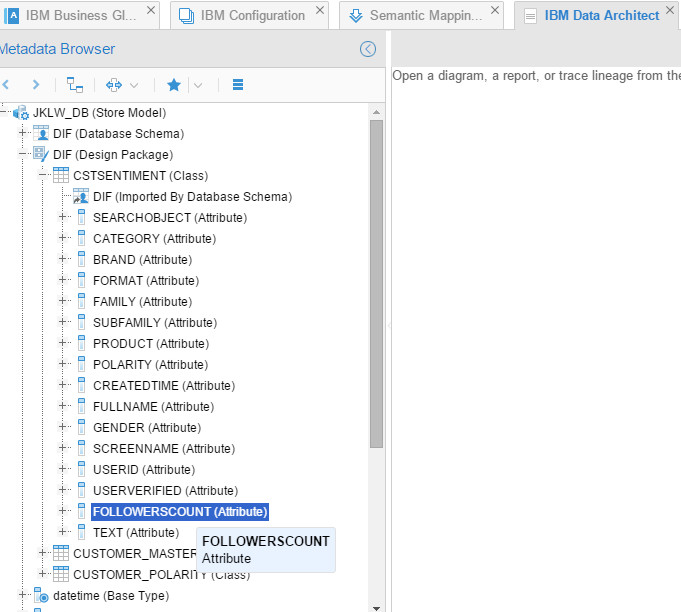
And it took me to the exact column:
Conclusion
I could harvest the IBM’s integration stack using native bridges shipped with OEMM. I could stitch them together easily, run lineage analysis and impact analysis. I was also able to build a business glossary from one of the IBM models easily, and then use the populated terms to trace the semantic usage. This experiment proves not only the ability of OEMM to manage IBM’s integration stack metadata, but also the heterogeneity of the solution to work with non-Oracle technologies.
Having an Enterprise Metadata Management solution is a must to any organization seeking data governance, reducing risks and ensuring data quality across all processes.
If you have any questions, please do write in the comments area. Until the next post, have a good one, and happy holidays!
Cheers