I know I’ve promised in my first OEMM article to start with OEMM series of articles to teach you how to install/configure OEMM all the way to fully administer it. But I woke up this morning with the excitement of trying OEMM with “Big Data.”
In this article, I will go through the steps that I made in order to have OEMM harvest from Oracle Database, MySQL, Oracle Data Integrator, BI and HDFS (via Hive). All of them stitched together, showing me full data lineage and impact analysis. It’s a pretty cool experience and easy to implement.
This article tends to be more of “what can be done in OEMM” rather than “how it can be done”.
Ingredients
Oracle Big Data Lite 4.0.1 VM: A fully integrated VM that comes with so many things to list here, so just visit this page and have a look. For the purpose of this experiment, we’ll be using ODI 12c, Hive, MySQL and the Oracle Database 12c in the VM.
OEMM VM: This is my own customized VM; it has OEMM 12c first release, OBIEE Oracle DB XE (as a repository for OEMM) and Hive 0.12.0 client driver.
My Oracle Linux 7 (container of the VMs) machine having Oracle VirtualBox-4.3.20 runs the preceding two VMs.
None of the above really matters to know, but just to give you a slight idea of how this experiment has been executed.
Scenario
I’ve used the Big Data Lite VM famous imaginary Oracle Movie Company to build my case. So what I’ve done in terms of integration is the following:
- Load movies from MySQL to Hive using Sqoop (via ODI)
- Transform Hive Movie data (without loading data outside) using ODI
- Do more transformations within Hive using ODI.
- Load movie data from Hive into Oracle Database using ODI
- Join Oracle and Hive tables using Big Data SQL (via ODI), do some aggregation and load into Oracle table.
To make my task in OEMM more challenging; I’ve decided to create an OBIEE report based on the integration I’ve done. (wasn’t the smartest idea as I’ve never ever created any report or worked with OBIEE, but was a good lesson for me). This way, we have raw data sources (Oracle, MySQL and Hadoop’s), ODI transformations, loading into some tables within Hadoop and Oracle and then BI report. Should be pretty cool to see their metadata in OEMM and run some linage, impact analysis and maybe import Hive into a Business Glossary?
The Execution
Step 1
Creating the ODI Mappings: They are already shipped with Oracle Big Data VM, let’s have a quick look at them:
A – Load Movie (Sqoop)
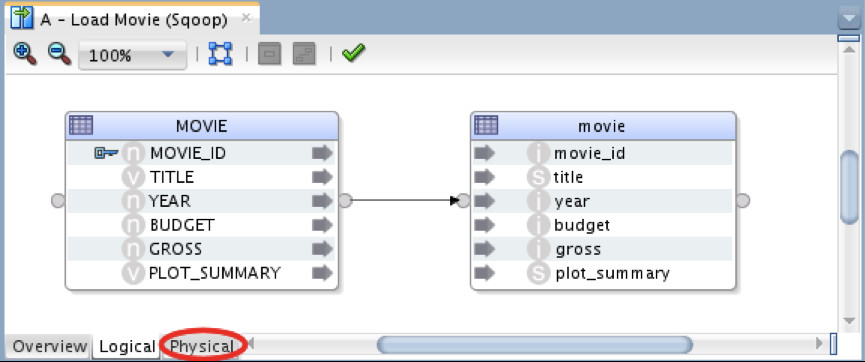
Pretty straightforward, simply mapping MySQL table into Hive table. IKM used is “SQL to Hive-HBase-File (SQOOP)”
B – Calc Rating (Hive)
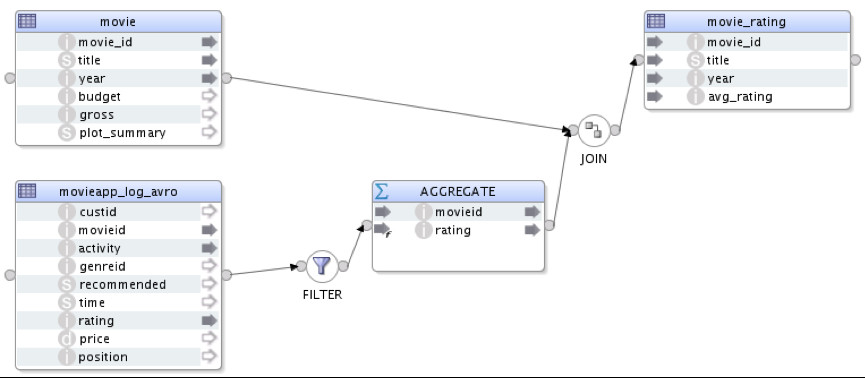
In this mapping, I’m doing some aggregation to my Hive data within Hadoop itself, which means I am NOT moving data outside Hadoop in order to do it. Source, staging and target all are within Hadoop itself. The mapping itself is self-explanatory. IKM used is “IKM Hive Control Append”, and there is only one physical execution unit.
D – Transform Activities (Hive)
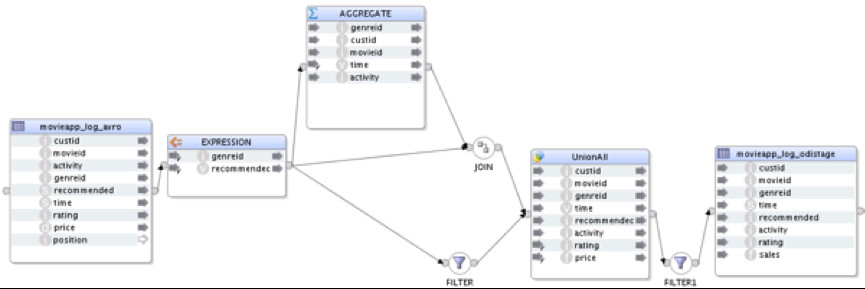
This mapping is pretty much the same as the preceding one in terms of where data is residing and being transformed, just making the transformation a bit more challenging.
C – Load Oracle (OLH)

In this mapping, I’ve used the Oracle Loader for Hadoop (via ODI) to load MOV_RATING table in Oracle Database from Hive. IKM used is “IKM File-Hive to Oracle (OLH-OSCH)”
E – Calc Sales (Big Data SQL)
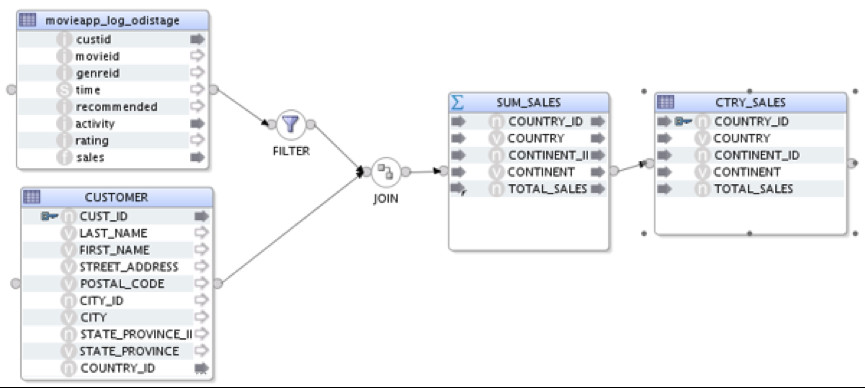
On this last mapping, I’ve used Oracle Big Data SQL in order to join data from Hive and Oracle. LKM used is “LKM Hive to Oracle (Big Data SQL)”.
Step 2
As I’ve mentioned earlier, I wanted to make this experiment more challenging so I decided to create an OBIEE report that links to one of the target tables I’ve used in my ODI mappings. The design process is out of scope for this article. What you need to know is that this report is using the table populated from the mapping “E- Calc Sales”. Nothing fancy 🙂
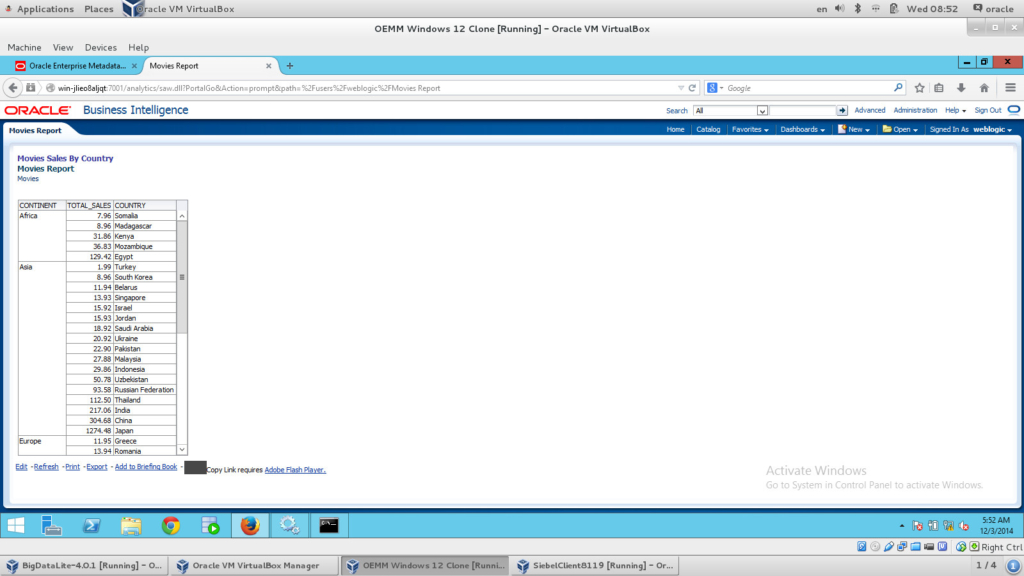
Step 3 (A)
This step involves all the work on OEMM. I’ve created a folder called “Big Data” in my OEMM Repository browser panel to gather everything in one place. Let’s now harvest our models; the following are screenshots after the harvesting is done:
The Oracle Model
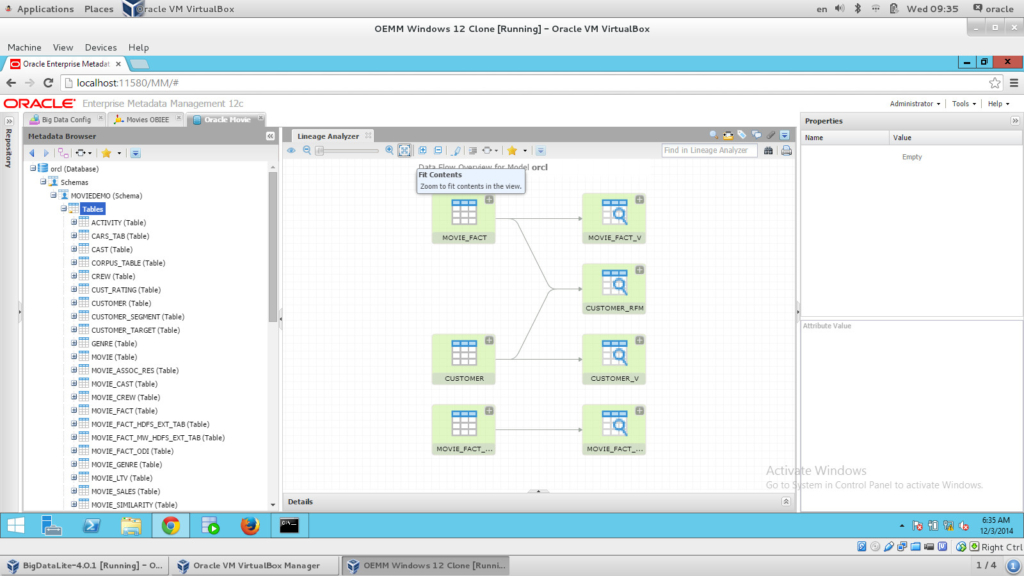
The ODI Model
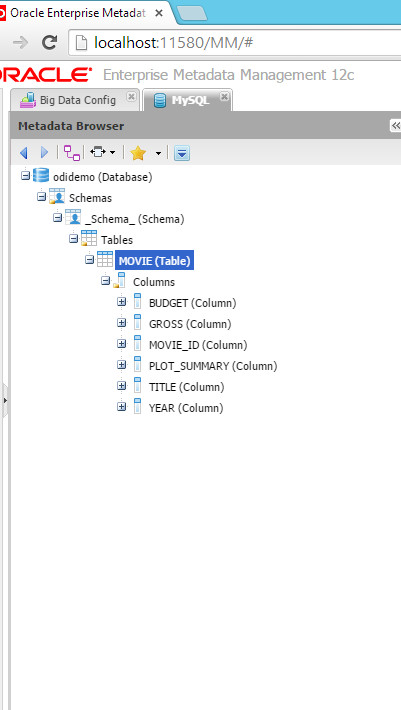
MySQL Model
While there is no dedicated bridge for MySQL (yet), I’ve used the generic Database (via JDBC) Bridge, which uses ODBC. In Windows ODBC, I’ve created a DSN that connects to the MySQL database. This step proves that OEMM can virtually harvest from ANY metadata provider.
OBIEE Model
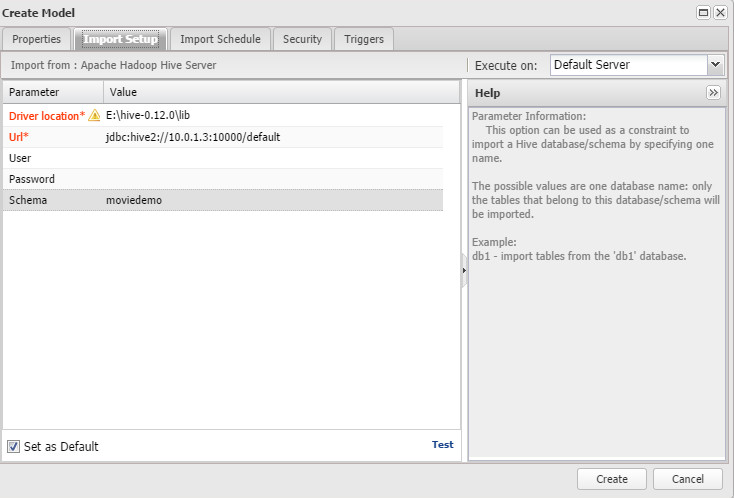
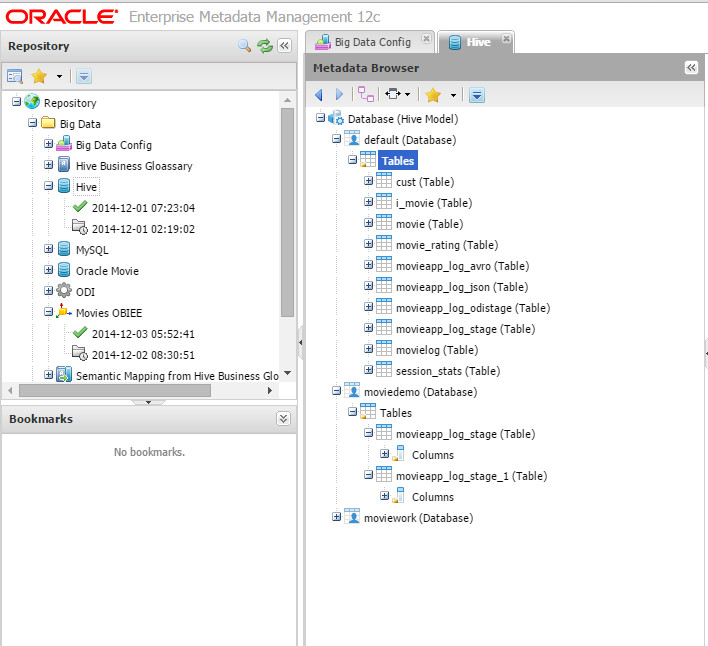
Hadoop Hive Model
This was the exciting one for me. It’s pretty straightforward though, I simply choose the bridge, put the connection string and pointed to the hive driver location.
Step 3 (B)
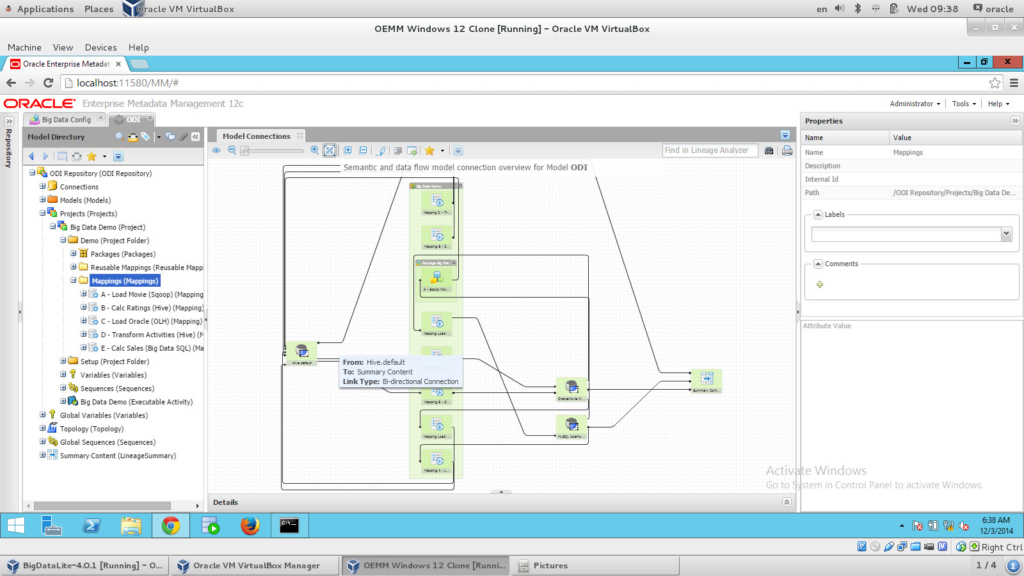
Now I have everything “harvested”, let’s get to “stitching”. In order to stitch models with each other, we need to create a Configuration. A Configuration in OEMM is a container for all models that you want to stitch and work with (generally). The process is very straightforward, simply drag and drop your models and “Validate” them to get something like the following architecture diagram:
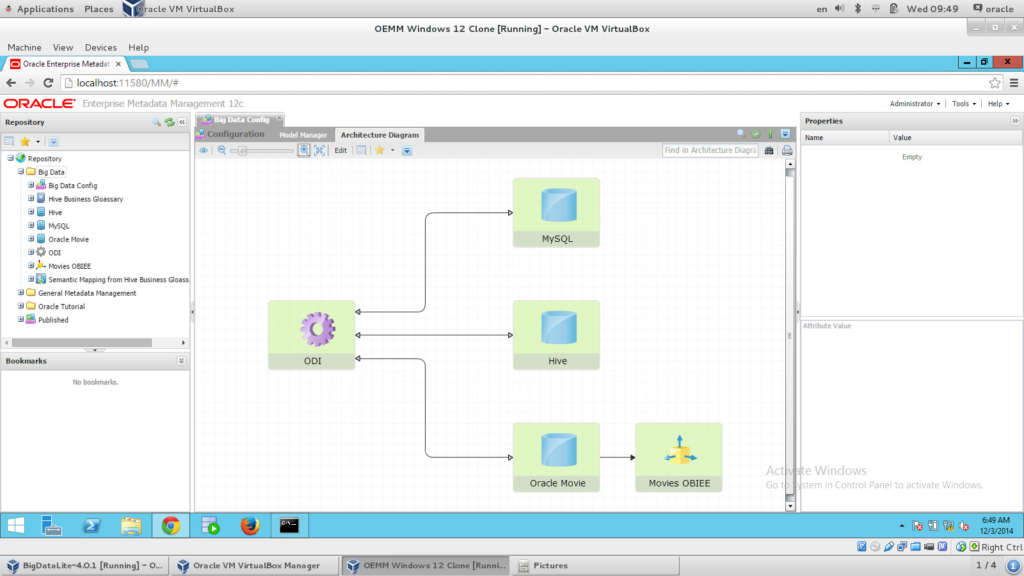
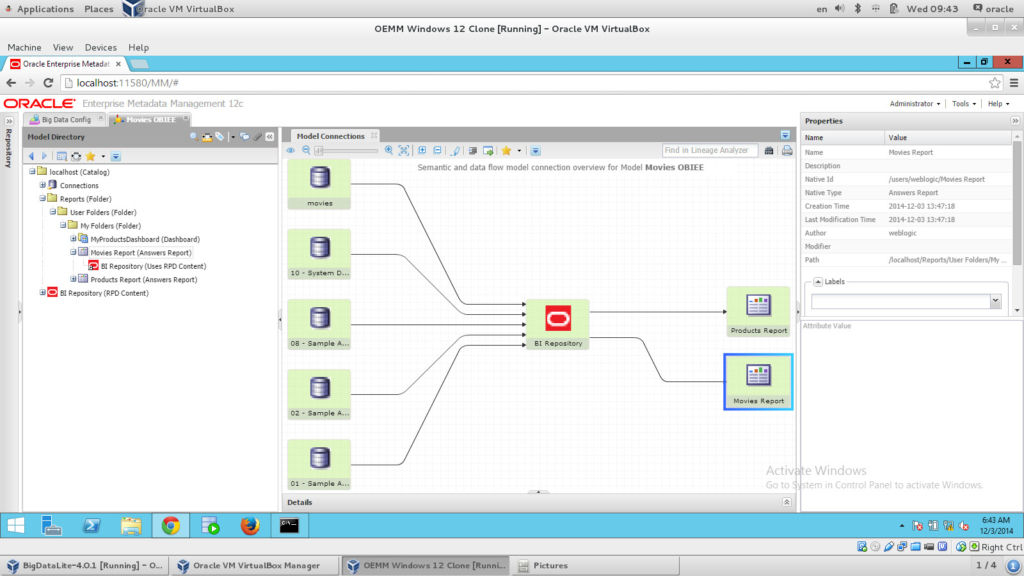
Now I have my configuration stitched, I can drill down into the diagram and see the metadata of each model, run impact analysis and lineage analysis. Let’s do a “Lineage Analysis” on our “Movie” BI report:
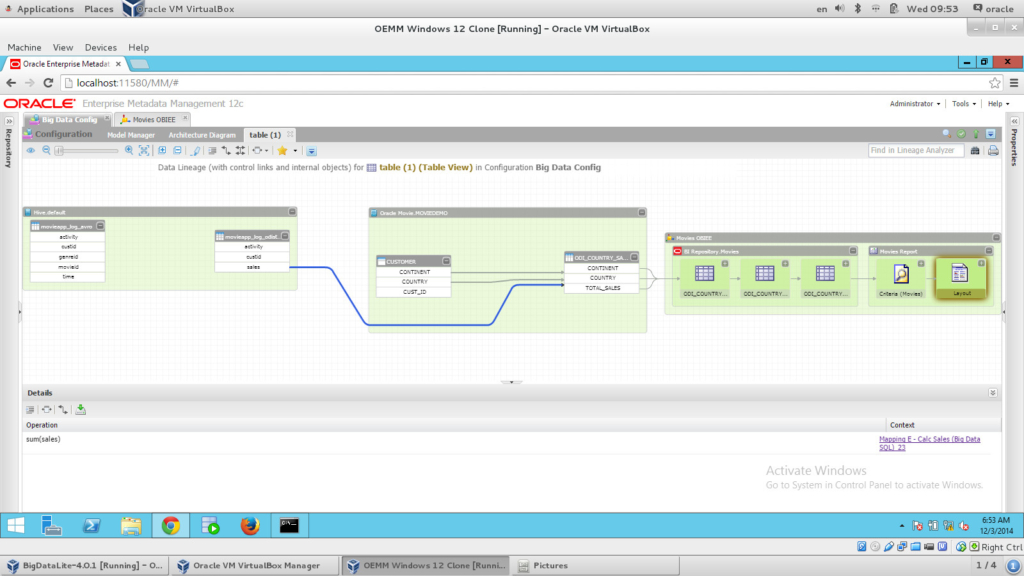
How beautiful is the above image? I could see FULL data lineage flow from my Hive all the way to the report. We started to extract from Hive, then via ODI (I clicked on the arrow link, the blue one, which shows the ODI mapping in the Details panel at the bottom), which loads into the Oracle table, and then OBIEE picks up the results and presents them in a report. You can even drill down into the ODI mapping level by simply right click on the link (the blue one here) and choosing “Trace ETL Details”, which will show something like the following:
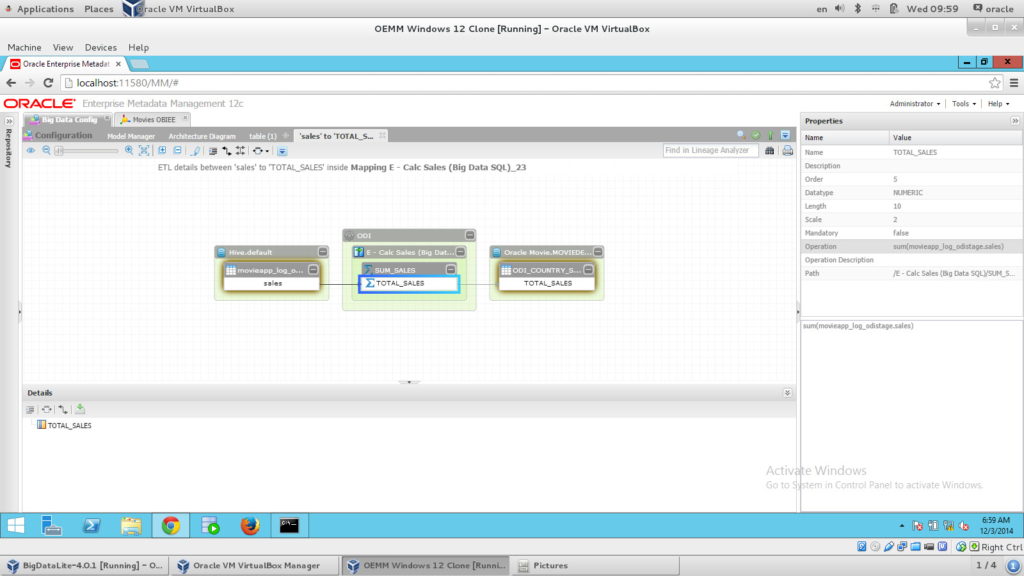
Notice how elegantly OEMM has put the aggregation/s, and if you click on it you’ll be able to see the operation for that aggregation on the Properties panel on the right side
Now Let’s run an “Impact Analysis” on the column “sales” in my Hive table, and see who would be affected if I change anything on that column:
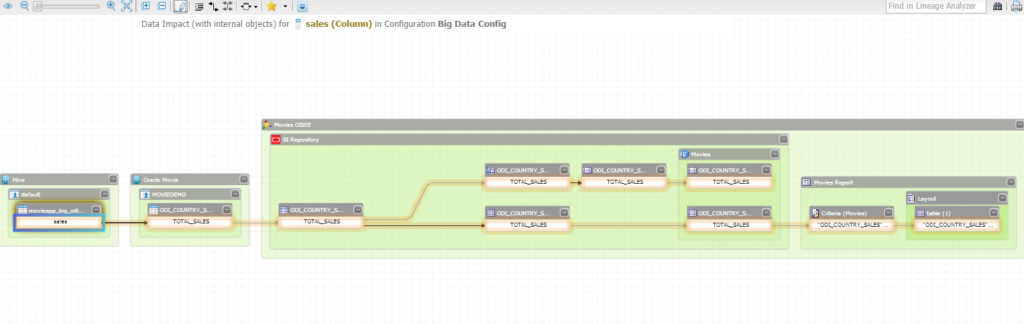
The image is self-explanatory; this just can’t be any simpler. What I’m doing to generate what you are seeing is literally a right-click and then selecting a command.
The last thing I wanted to check is the ability to generate Business Glossary from my Big Data source, Hive. And that was another easy process, I simply created an empty Business Glossary, dragged and dropped my Hive Model, and the following was ready for me:
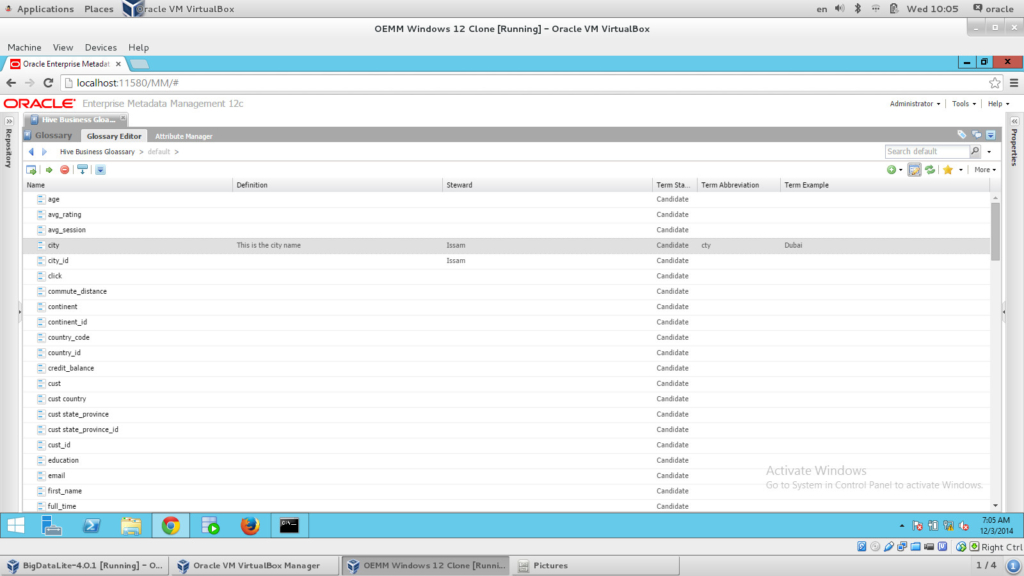
There are tons of other things I can do with OEMM such as semantic analysis, versioning, manual mapping, comparing, etc… But the purpose of this experiment is to show you that OEMM is Big Data ready, and you can start using it right away to harvest all your Big Data sources, and make sense of the metadata within.
Conclusion
Several conclusions I came up with such as that OEMM work with Big Data sources (via Hive for instance) like any other “relational” data model. The process of harvesting, stitching and running impact/lineage analysis cannot be any simpler. OEMM is Big Data ready without a doubt, and to start using it you don’t need to be an expert, just a normal business user. I’ve accomplished all this in 1 day (including the OBIEE learning part), with limited computing resources and still managed to have it successful.
Stay tuned for more OEMM stuff soon.
Issam