“MapR-FS is a POSIX file system that provides distributed, reliable, high performance, scalable, and full read/write data storage for the MapR Converged Data Platform. MapR-FS supports the HDFS API, fast NFS access, access controls (MapR ACEs), and transparent data compression. MapR-FS includes enterprise-grade features such as block-level mirroring for mission-critical disaster recovery as well as load balancing, and consistent snapshots for easy data recovery.”
Reading that leads to the conclusion that MapR-FS is not just HDFS, it’s MapR’s enhanced, and property , version of HDFS that gives you more flexibility and better control, I’d say, from enterprise level. According to MapR, it’s fully HDFS API compliant, which was something I wanted to test myself and see if would work with Oracle’s solution, GoldenGate. Previously, I wrote a blog showing how to stream transactional data into MapR Streams using Oracle GoldenGate.
“Oracle GoldenGate for Big Data 12c product streams transactional data into big data systems in real time, without impacting the performance of source systems. It stream lines real-time data delivery into most popular big data solutions, including Apache Hadoop, Apache HBase, Apache Hive, Apache Flume and Apache Kafka to facilitate improved insight and timely action.”
For this experiment, I’ve used my “enhanced” version of MapR’s Sandbox 5.1. In this Sandbox, I’ve:
1. installed Oracle GoldenGate 12c for Non-Oracle Database (12.2.0.1.0)
2. installed Oracle GoldenGate for Big Data (12.2.0.1.0)
3. upgraded MySQL from 5.1 to 5.7 (for extra cool reasons beyond this blog, so keep watching my blog-space)
Source Configuration
It’s just another simple OGG configuration that captures committed transactions from the database logfiles, which is MySQL in the experiment. I’ve used MySQL sample database “Employees” for the sake of this blog.
Here is the extract parameter file:
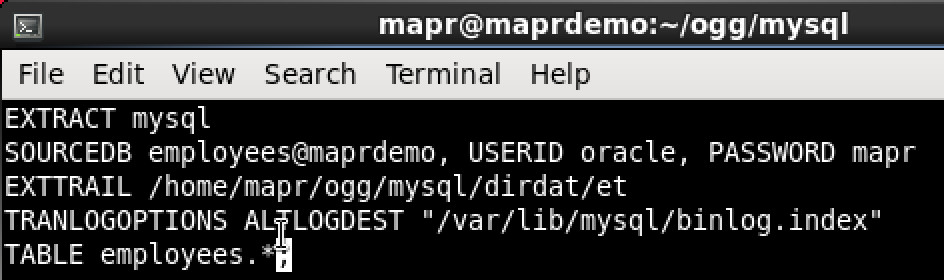
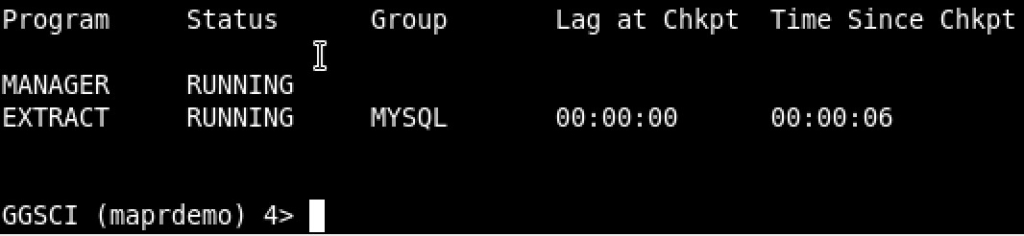
Nothing special there, I’m capturing all changes from employees database, and writing them into some trail file. Here is the extract up and running:
Target Configuration
Here I configured OGG replicat process to write changes that are captured from OGG source into MapR-FS. Here is how the parameter file looks like:
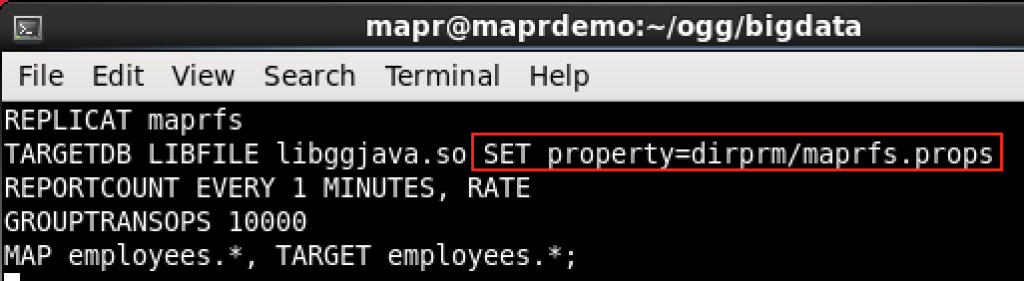
Again, nothing special in the parameter file except that it points to a properties file, which handles the communication between OGG and MapR-FS. Let’s have a look at it:
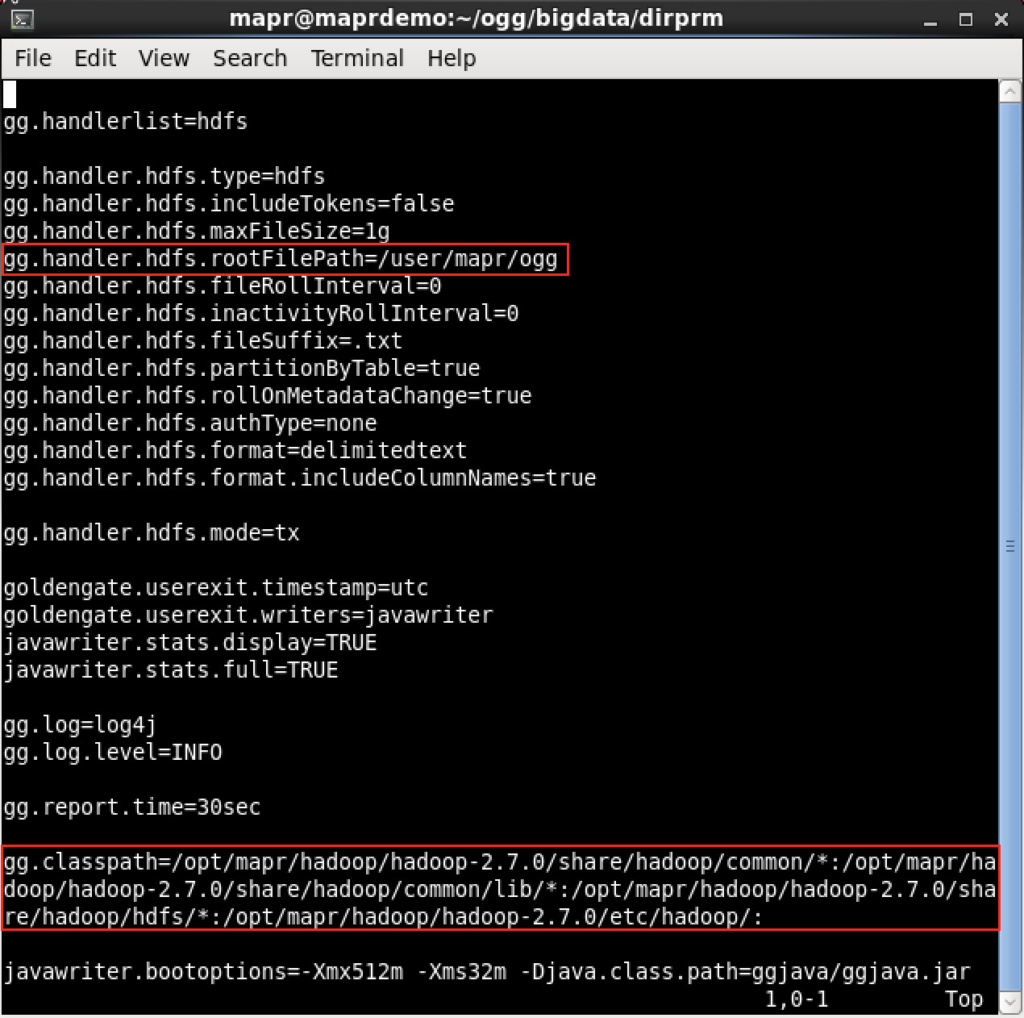
I’ve used the supplied template that comes with OGG installation and changed only two parameters: rootFilePath and classpath: rootFilePath is where OGG will write the captured transactions in MapR-FS, and classpath is pretty much MapR’s jars. Notice that I’m using here the “hdfs” handler, as there is no specific “MapR-FS” handler in OGG. Here is the replicat process up and running:

Results
Now both source and target processes are up and running, I simulated this experiment by inserting some random records into MySQL employees database. Checking OGG source stats to verify:
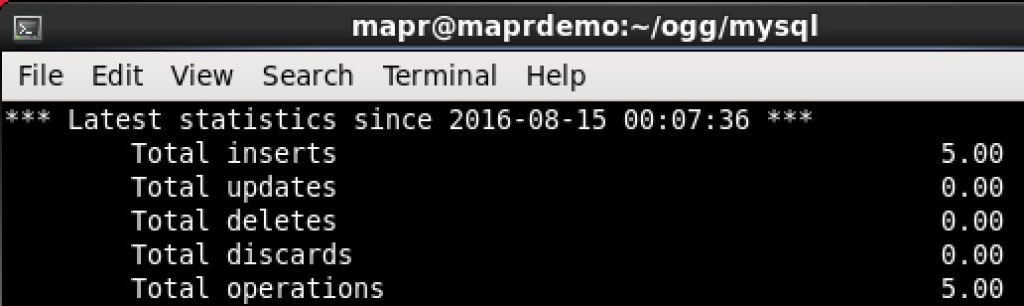
CHECK. And target stats:
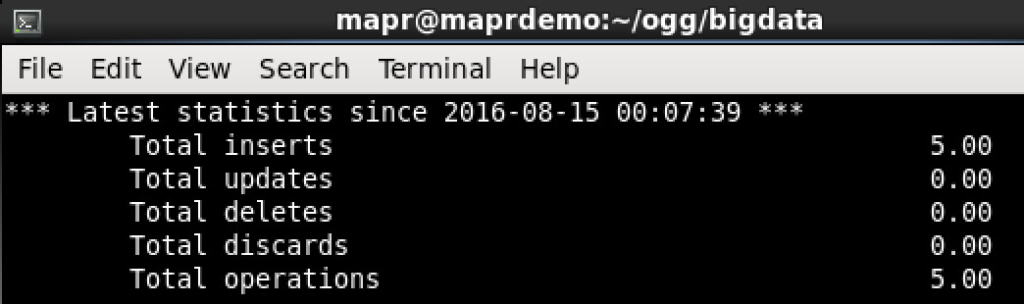
CHECK. Now into MapR-FS:
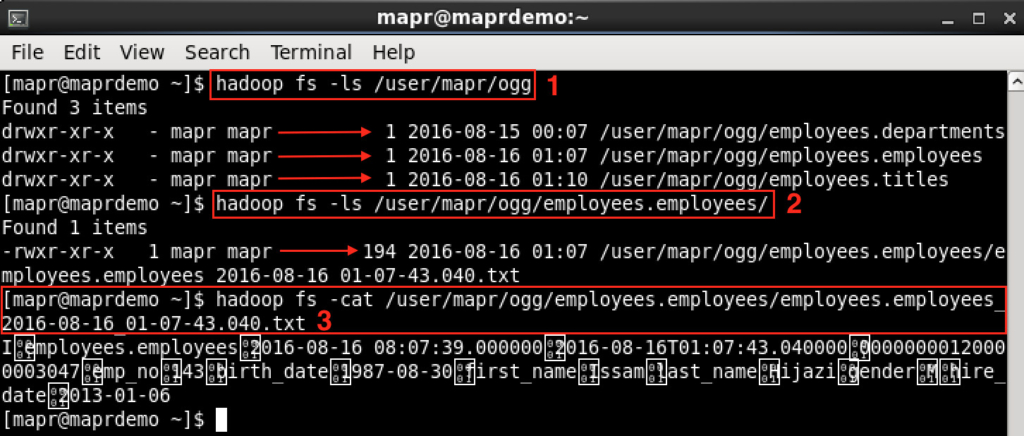
- Checking the OGG directory, notice that for each table OGG has created subdirectory.
- Checking one of the created subdirectories, notice OGG has created txt file as per my configuration in OGG (which you are free to customize)
- Checking the content of the preceding file, I see the one record that I’ve inserted into that table is replicated.
Conclusion
Oracle GoldenGate for Big Data is a reliable and extensible product for real-time data, transactional level, delivery. From this experiment, I was able to integrate with MapR-FS exactly the same way I’d integrated with stock Apache Hadoop HDFS.
Are you on Twitter?
Then it’s time to follow me @iHijazi