Today I came across this request: “We need to copy our data efficiently between two Hadoop clusters, via ODI. Can we?”.
When it comes to ODI, I cannot think of a case where I ever said no, thanks to its modular architecture, flexibility and extensibility. While there is no “official” KM yet shipped with ODI for this specific purpose, this blogs shows a great example of how and when you may need to do some “customization”, create a new KM (knowledge module) to meet your needs instantly without being locked to vendor development/releases.
Before I move on, I would like to clarify the heading image: do not worry, it won’t take that long!
Let’s set the bases first of how this going to work. Apache Hadoop has a tool called DistCp (distributed copy) which is “used for large inter/intra-cluster copying. It uses MapReduce to effect its distribution, error handling and recovery and reporting. It expands a list of files and directories into input to map tasks, each of which will copy a partition of the files specified in the source list. Its MapReduce pedigree has endowed it with some quirks in both its semantics and execution. The purpose of this document is to offer guidance for common tasks and to elucidate its model.” So it makes sense to utilize that efficiently and natively, right?
For such a job, ODI is a perfect fit. It already executes 100% of its code natively on Hadoop, so why not this one, too?
I have created an integration knowledge module and called it “IKM HDFS-HDFS DistCp“. To automate and orchestrate the preceding in ODI, natively, you may use this KM and improve it (if needed) to suit your environment. Please note that this is not an official Oracle KM, and my intention here is to give you an idea of how to handle such situations when no KM is available to serve your immediate needs.
Click here to download it (from java.net)
IKM HDFS-HDFS DistCp
This KM utilizes Apache Hadoop DistCp component to provide the functionality described in the beginning of this document. It has a set of options that are fully compatible with the tool interface:
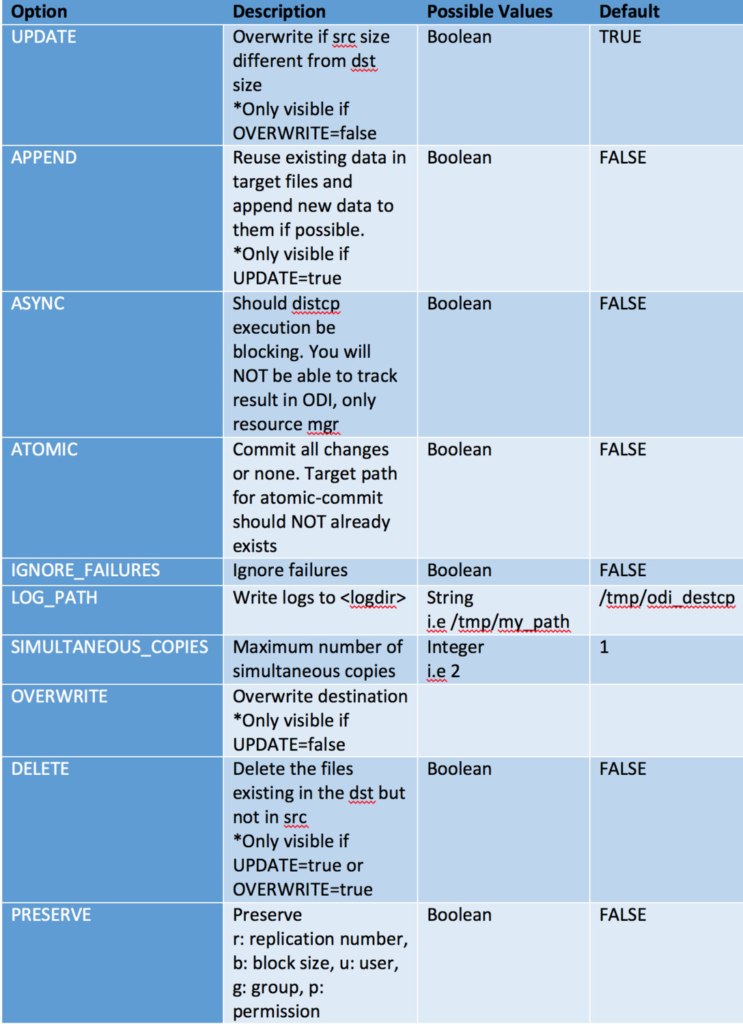
Example
The following guide illustrates how to use the KM to replicate?/copy HDFS data from “Cluster A” to “Cluster B”.
Step 1: Getting the project environment ready
A) Import Knowledge Modules into your ODI project or ODI Global scope
B) Create two New Data Servers under File Technology; one for “Cluster A”
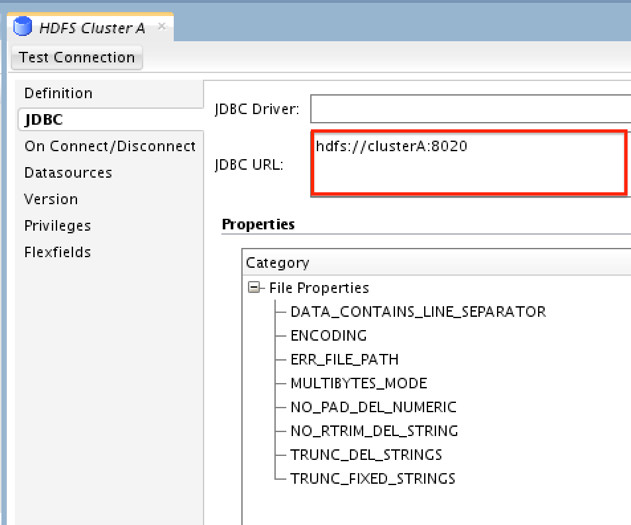
and another for “Cluster B”
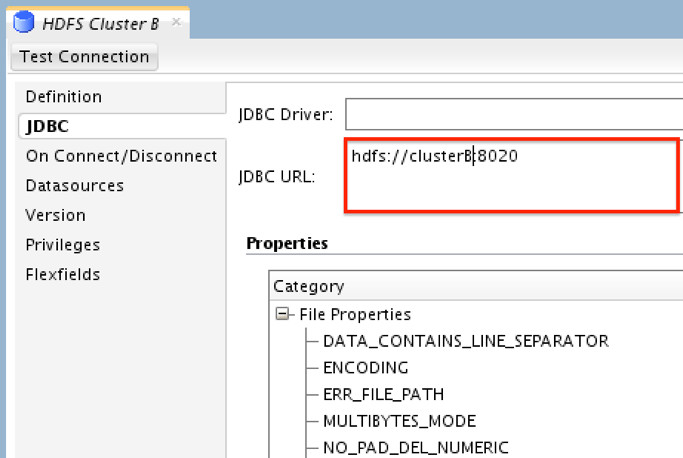
**We only need to point the JDBC URL to the namenode URI for cluster.
C) Create new Physical Schema for each of the preceding data servers. Directory value here should be the path which we’ll be copying from “Cluster A” (for Cluster A data server) and “Cluster B” target path (for Cluster B data server). i.e for “Cluster A”
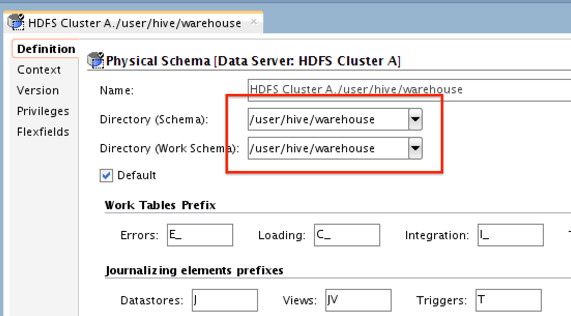
and for “Cluster B”
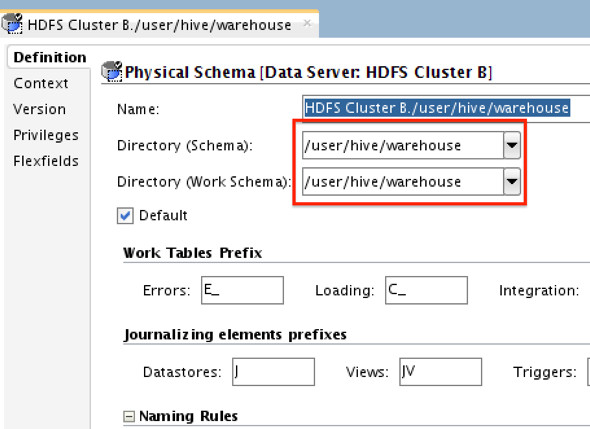
**Directory path on target does NOT have to be the same as the one on the source.
D) Create New Logical Schemas for both clusters pointing to the preceding physical data servers.
Step 2: Defining the “Data Models”
A) Create Models (data models, that is) for “Cluster A” and “Cluster “B”. Specify the technology (File) and the Logical Schema we created previously for “Cluster A” and “Cluster B”. i.e for “Cluster A”:
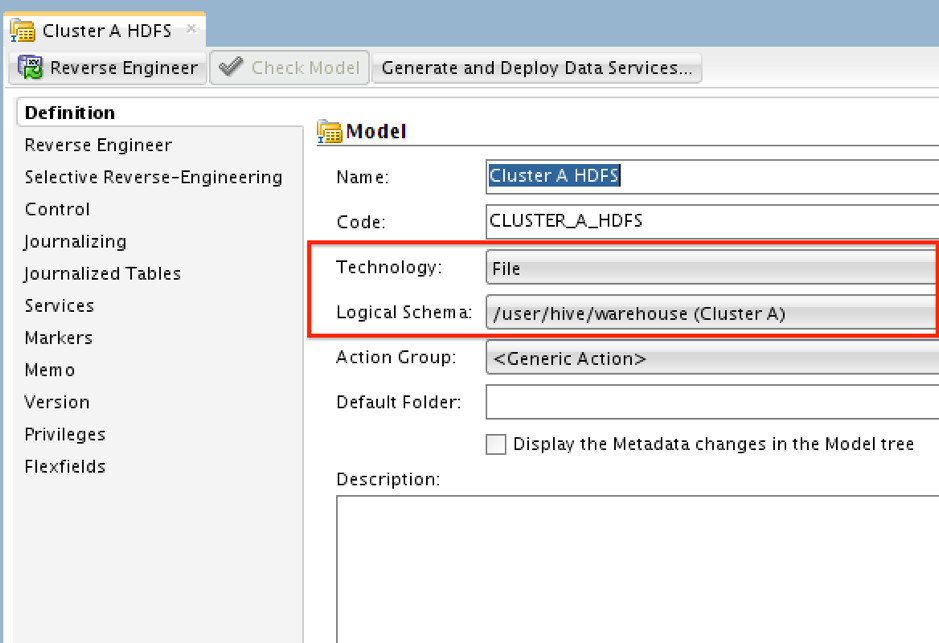
B) Create New Datastore under the preceding data models for both clusters. Note here it’s just a “dummy” data store with no attributes. When creating them, set the “File Format” to “Fixed” so you don’t get complains, and leave everything else as is.
Step 3: Creating the Mapping
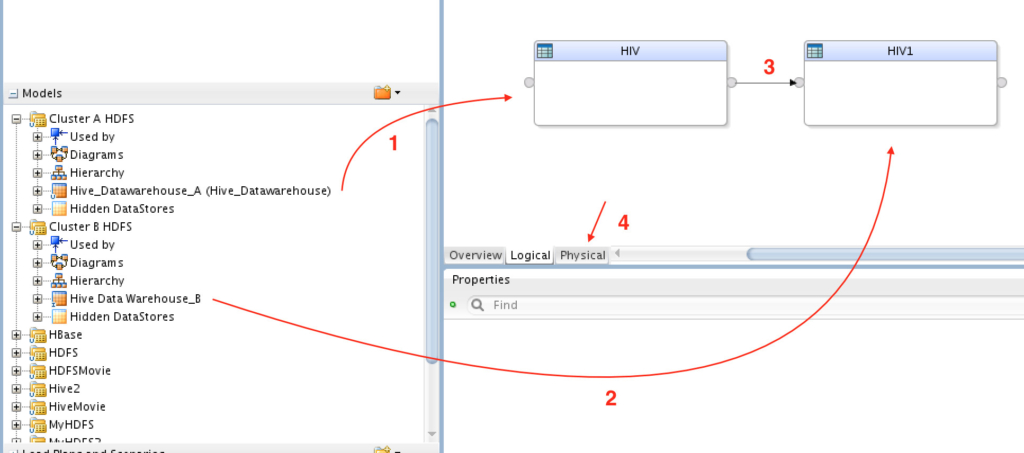
A) Drag/drop “Cluster A” to the canvas => Do the same for “Cluster B” => Now connect “Cluster A” to “Cluster B” (just like you normally would for any other mapping…) => Click on Physical tab.
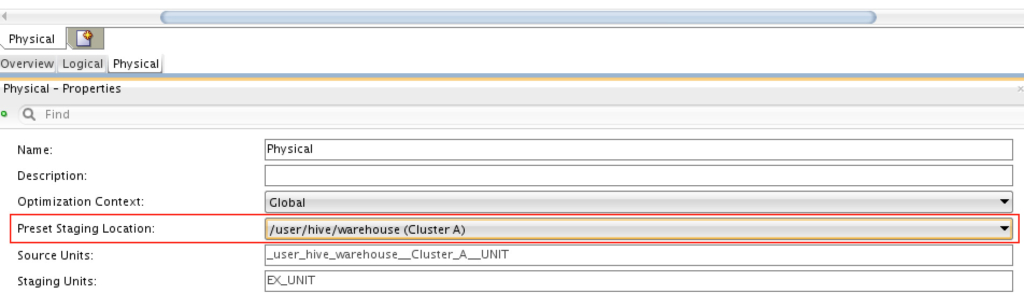
B) Then we need to set the staging location to the source (“Cluster A” in this example):
C) Now drag and drop “EX_UNIT_” from the middle target group to the last one, so we only have two execution context here:
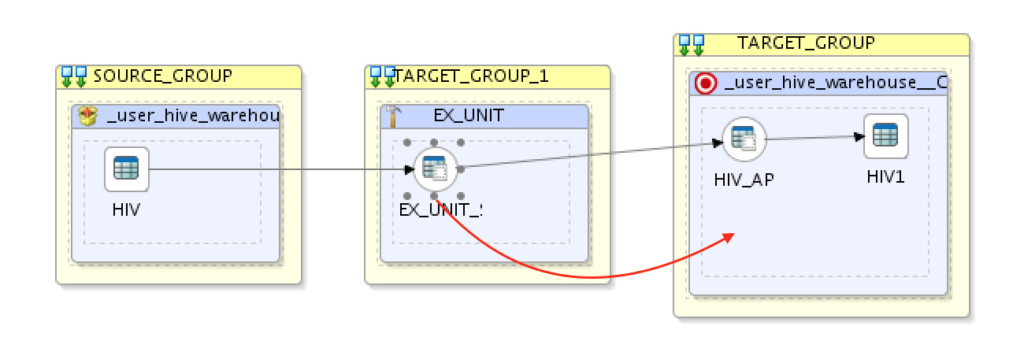
D) Next we need to set the loading knowledge module to “LKM SQL Multi-Connect”:
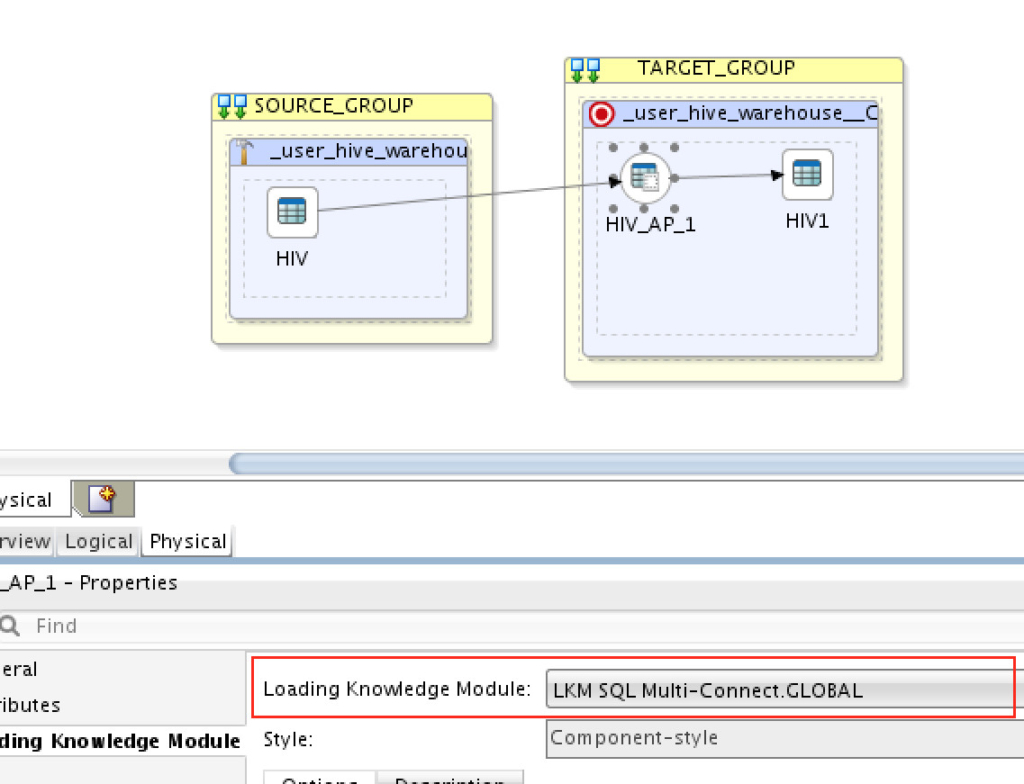
And finally, set the integration knowledge module to”IKM HDFS-HDFS DistCp”:
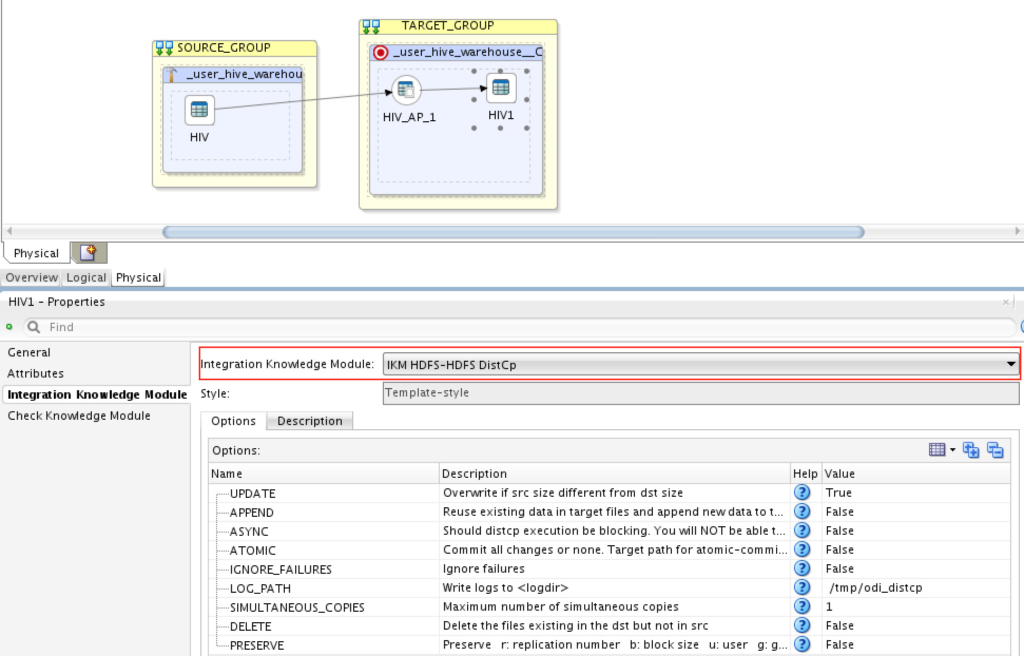
**You may change the options to suit your requirements.
That’s it! Now you may run the mapping to test it. Navigate to “Operator” tab to monitor the results (and explore what’s happening behind the scene):
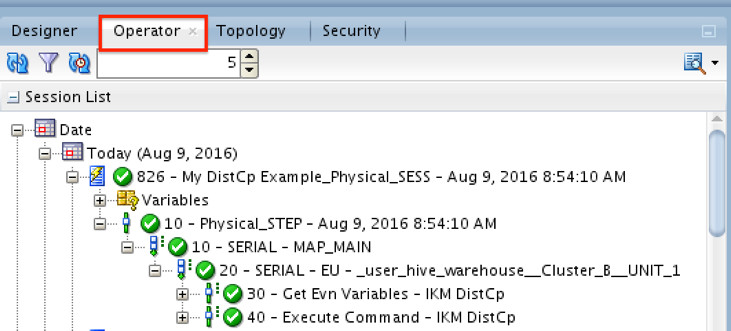
The elephant has been copied across clusters!
Conclusion
Oracle Data Integrator makes a great tool for adopting new technologies and techniques immediately. Copying data between clusters cannot be any easier now using the above KM. Moreover, this mapping can be scheduled as needed so your clusters are synced as per your requirements.
Are you on Twitter?
Then it’s time to follow me@iHijazi