While almost everyone talks about it, I thought of actually doing it. When we talk, present and educate people about Big Data, we tend to mention “Twitter” as a great example, we also get into the steps taken to deal with Big Data using Oracle’s Big Data 3-Phase Design:
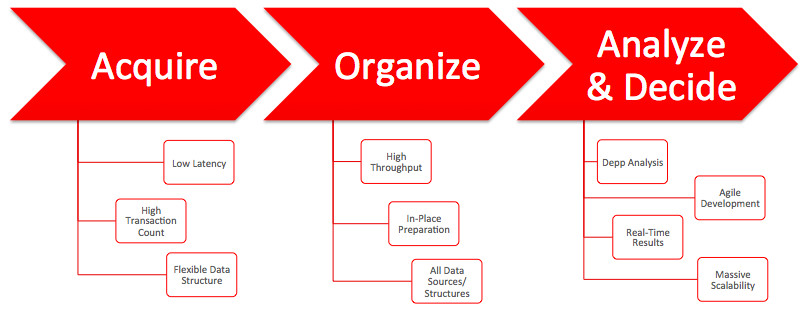
That’s awesome, I mean the theoretical part, but it’d be “epic” to see it in action, no?
In this post, I’ll show you “high-level” steps that I’ve taken to get feeds from Twitter into HDFS via Flume, and having Hive on top of the sunk data to work with them. I’ll also show you how Oracle Data Integrator (ODI) can easily “reverse-engineer” the tables I have created in Hive, extract data from Hadoop, transform within Hadoop and eventually load them into a relational database, Oracle Database.
Ingredients
Because life isn’t always easy, setting up Hadoop and its “technologies” isn’t a walk in the park and requires deep knowledge and understanding of this framework. Thanks to Oracle Big Data Appliance, I didn’t have to start anything from scratch. You may fully experiment with Oracle’s BDA by downloading a ready-to-use VM with lots of tutorials and materials around it from here. Go ahead, download it, it’s free for learning purposes!
Having said that, my main component in this experiment was “Oracle Big Data Lite VM”, which is loaded with a bunch of Hadoop technologies, and pretty much pre-configured. In the VM itself, I’ve used:
1. Hadoop Framework
2. HDFS
3. Hive
4. Flume
5. ZooKeeper
5. Oracle Database
6. Oracle Data Integrator
Explaining each of the above is out of scope of this post. But the good news is that there are plenty of resources on the internet. Please note that those are the “obvious” components I’ve worked with directly, however they do utilize other components in the background.
I’ll explain why I’ve used Flume in my experiment: The easy answer is because it’s easy. Flume has set of “sources” and “sinks” which makes life easier:
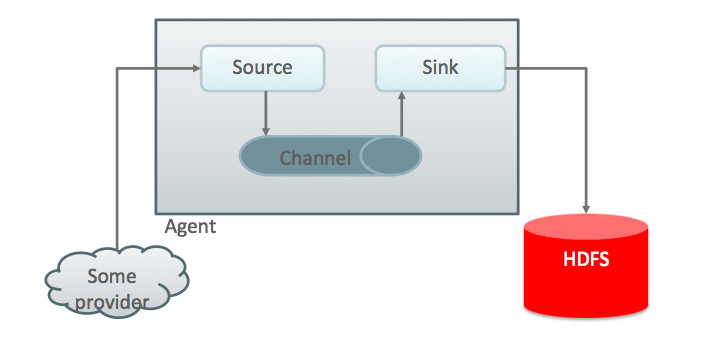
As a source, I’ve used a pre-configured and ready-to-use source for Twitter, which makes use of a great open-source SDK called “twitter4j” that fully covers Twitter’s APIs using Java. Having that, I’ve eliminated the need to create my own Java application to capture feeds from Twitter and then pump them to my “Flume” agent. Simply, this one flume agent does it all.
The Execution
Certain logistics need to be done before we get going. Let’s get to the action:
Step 1
Create a Twitter account if you don’t already have one. Then you need to visit Twitter’s developers section, https://dev.twitter.com/, have some education, then jump to https://apps.twitter.com/ to create an App. Not a literal App, just the Keys and Access Tokens which you will need while configuring the Flume agent. I won’t go through the steps here, but eventually you should have something like the following information from Twitter:
Step 2
Because I’m using Oracle Big Data Lite VM, the steps will vary in your case if you’re not. But in general, you need to make sure that CDH (distribution of Apache Hadoop and related technologies) is installed, configured, up and running And of course Oracle Data Integrator 12c. All in all, you need to have your environment ready to run, if you want the easy way use Oracle’s VM I’ve mentioned earlier.
Step 3
Let’s get into configuring our Flume agent. Remember, Flume in this case will be responsible for capturing the tweets from Twitter in very high velocity and volume, buffer them in memory channel (maybe do some aggregation since we’re getting JSONs) and eventually sink them into HDFS.
1. Download a pre-built customized Flume source from here.
2. Add the downloaded jar into the Flume classpath: /usr/lib/flume-ng/plugins.d/twitter-streaming/lib/ and /var/lib/flume-ng/plugins.d/twitter-streaming/lib/
3. Create flume.conf file, and edit its content to match your Twitter’s keys and Hadoop configuration. It should look something like this:
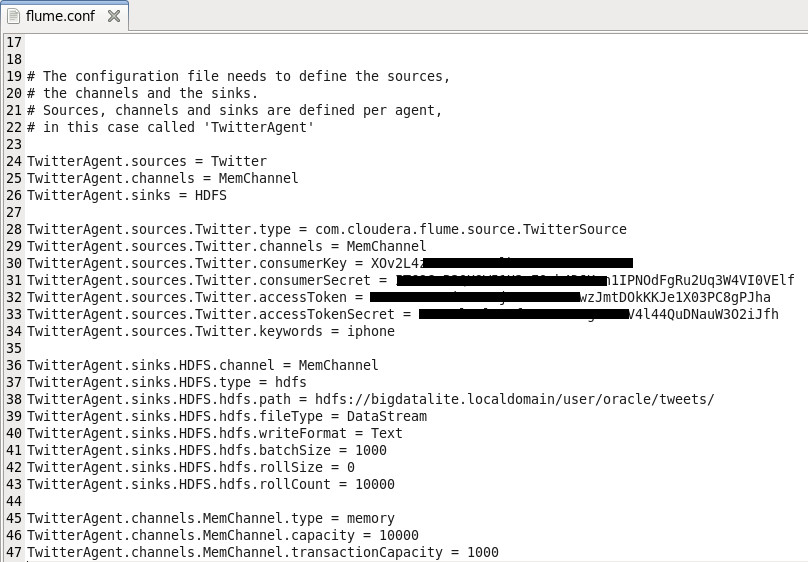
You may get the file template from here.
Step 3
Now let’s configure Hive:
1. We need JSON serialization/deserialization class. Download a pre-built version of JSON SerDe from here.
2. Create Hive needed directories:
$ sudo -u hdfs hadoop fs -mkdir /user/oracle/warehouse
$ sudo -u hdfs hadoop fs -chown -R oracle:oracle /user/hive
$ sudo -u hdfs hadoop fs -chmod 750 /user/oracle
$ sudo -u hdfs hadoop fs -chmod 770 /user/oracle/warehouse
3. Configure the Hive Metastore. Make sure you follow instructions here, and then make sure to install the MySQL JDBC driver in /var/lib/hive/lib. (I haven’t done this step since Oracle’s VM is already configured).
4. Run Hive and create a table called “tweets” with the following DDL:
hive> ADD JAR <path-to-hive-serdes-jar-you-downloaded>;
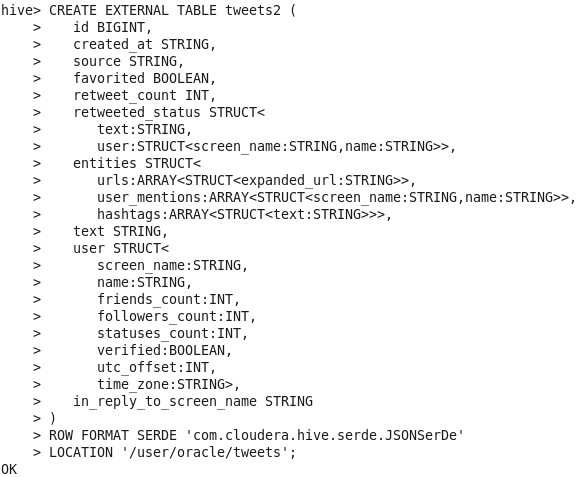
While I’m talking about creating tables, please note that I’ve created two tables in Oracle database to be used by the Mappings we’ll create later.
Step 4
Back to our Flume agent:
1. Create the HDFS directory hierarchy for the Flume sink:
2. Start Flume agent with the following command:

You should see in the console some information message stating that it’s running and writing to some files on HDFS (those are being appended from the filtered data stream captured from Twitter):
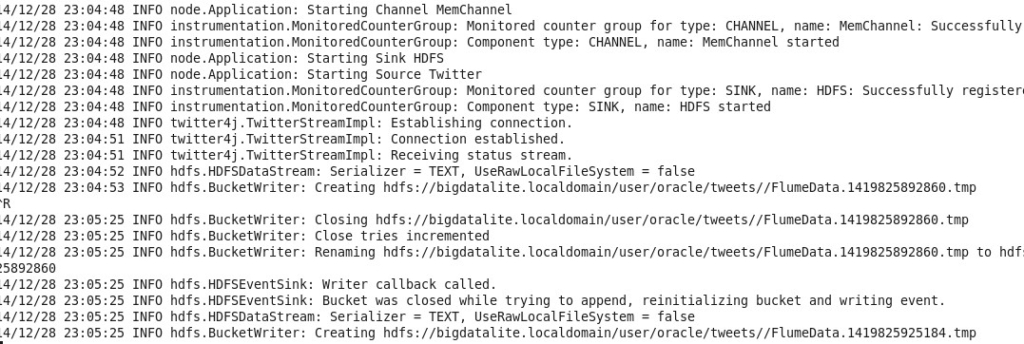
Leaving the Flume agent running for few minutes will create significant data for us to play with, so make sure you stop it after a short period. To check the files created on HDFS, go to Hadoop’s web console and browse, you should see something similar to this:
And if you browse any of the files, you’ll get something like this:

That was pure complex json. Let’s “select count” on Hive and see how many records we got:
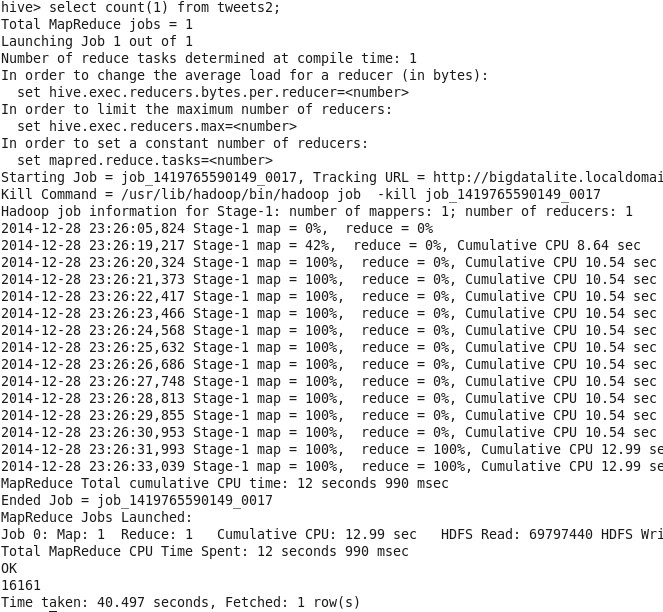
16161 records by just running my flume agent for few minutes on a currently somehow “low-tweeted” term, “iPhone”. Well, that’s big data with high velocity in action!
Step 5
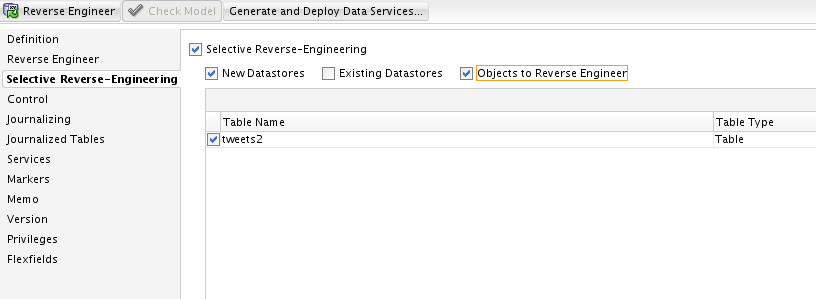
Now we have our Twitter data in HDFS, let me show you how ODI will be able to reverse-engineer the table we created via Hive. I’ve opened my model normally, and selected “Objects to Reverse Engineer” to show me those which I haven’t reverse-engineered yet, just like any relational model:
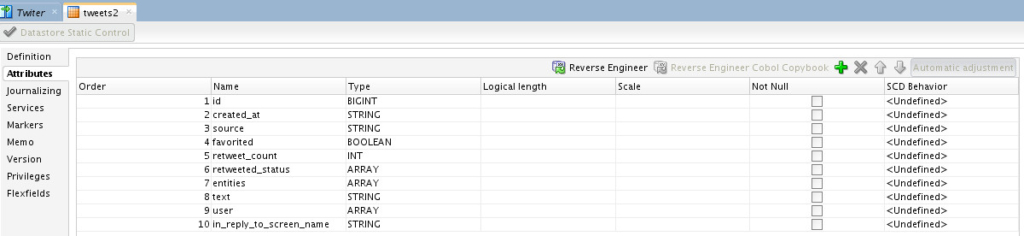
Once it finished the reverse-engineering process, I got the table metadata in ODI repository ready to be used:
The steps I’ve taken were pretty much the same steps I’d take to reverse-engineer any relational model. No magic. ODI uses specific knowledge modules in order to reverse engineer, load and integrate data in Hadoop. You’ll find KMs like RKM Hive, RKM HBase, IKM File to Hive, IKM SQL to Hive, IKM Hive Transform, CKM Hive, IKM File/Hive to SQL and much more. They are out-of-the-box, and you need to do nothing to use them, which means you do NOT need to know how to write MapReduce code, access HDFS, Hive or anything in order to process the data in HDFS. Your job is purely an integration job, same techniques you’d use with any relational database. Here is a quick look on how data look like in my Hive table:

As part of this experiment, I’ve decided to load/transform data within Hadoop, then move filtered/aggregated results to Oracle database. First, I’ve created an interface that will translate the following DML:
“SELECT t.retweeted_screen_name, sum(retweets) AS total_retweets, count(*) AS tweet_count FROM (SELECT retweeted_status.user.screen_name as retweeted_screen_name, retweeted_status.text, max(retweet_count) as retweets FROM tweets GROUP BY retweeted_status.user.screen_name, retweeted_status.text) t GROUP BY t.retweeted_screen_name”
Here is my “flow-based” and “declarative-designed” combined mapping:
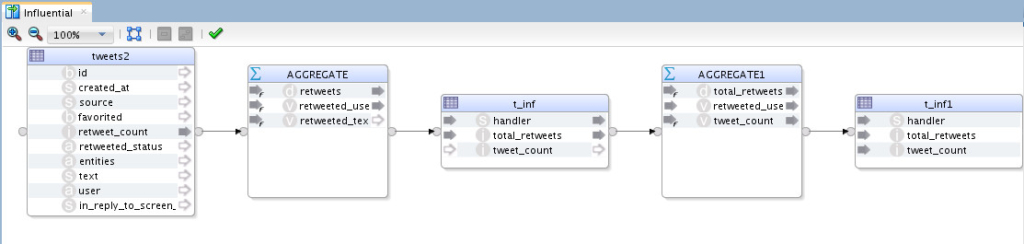
So I’m extracting data from my hive table, tweets, doing some aggregation, loading them into another Hive table (I’ve created this one on Hive), then do more aggregation and finally loading the final results into my target “Hive” table (same table I created before). If you noticed, I’m doing the whole cycle within Hadoop itself, I am NOT moving data outside to processes it. Physical design:
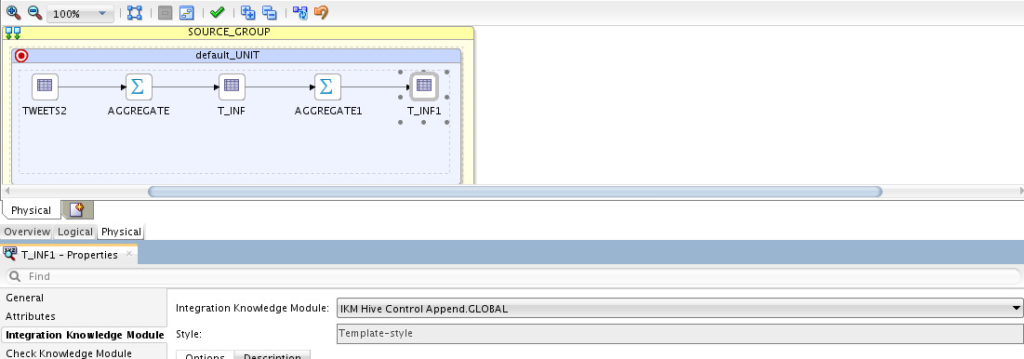
I’ve selected “IKM Hive Control Append” as the Integration Knowledge Module for my target table. Running this mapping resulted in:
It’s worth mentioning, again, that you don’t really need to know what’s happening behind the scene. ODI, via KMs, will be doing all the necessary steps for you such as creating external tables, MapReduced jobs, etc…
Now that my data has been “processed” within Hadoop itself, time to move them out for further use, could be BI? Logical design:

Going into Physical design, I choose Hive to Oracle (Big Data SQL) LKM:
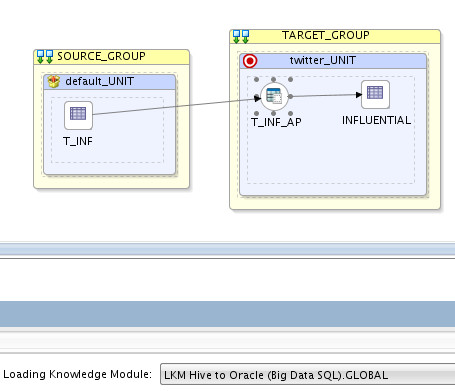
Running the mapping resulted in moving the data from Hadoop to Oracle.
Next I wanted to move data directly from Hive to Oracle with minor mapping of the complex data type (struct/array). I wanted to design the following DML in a new ODI interface:
“select user.screen_name, user.followers_count c from tweets“
Should be simple to do, here is how the logical view looked like:
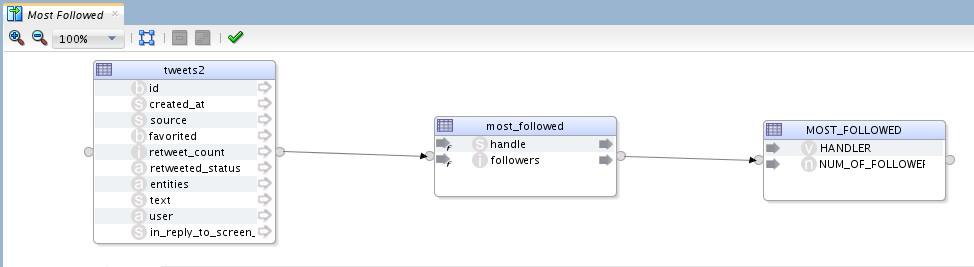
I’m extracting from “tweets” Hive table into a temp Hive table I created, and eventually loading them to Oracle database. The Physical design looked something like the following:
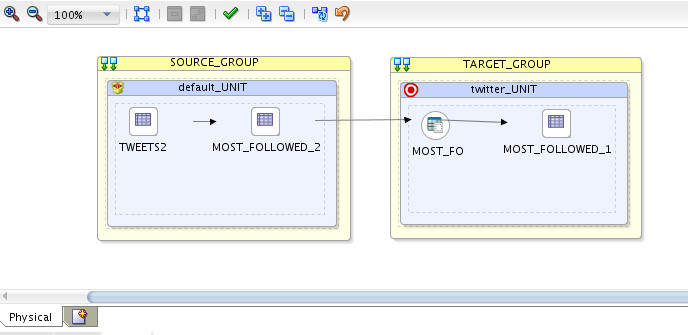
On the source, I’ve used IKM Hive Control Append to populate my temp table:
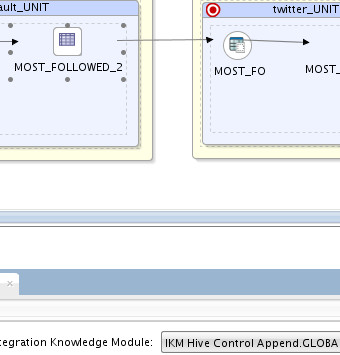
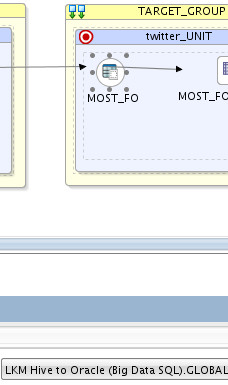
On the target, I’ve used LKM Hive to Oracle (Big Data SQL) to move data from HDFS (Hive) to Oracle database:
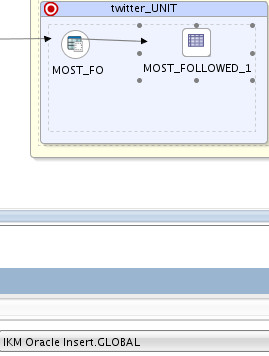
And finally, on target I’ve used “IKM Oracle Insert” since the data now is already in Oracle database:
Executing the mapping:
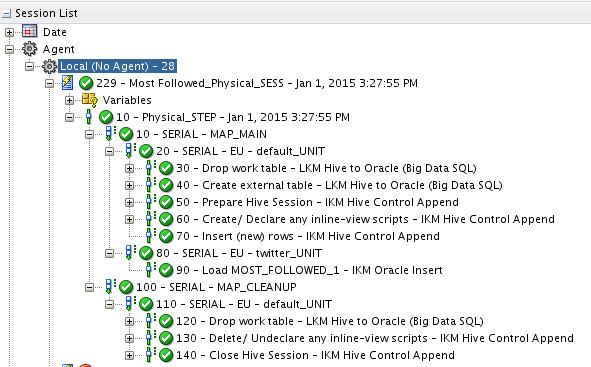
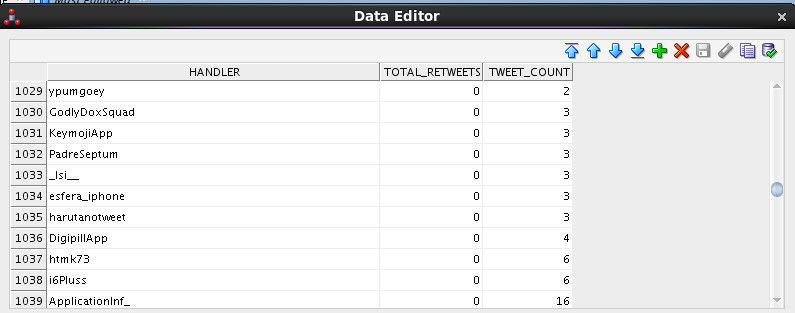
This resulted in populating the following data in my Oracle table:
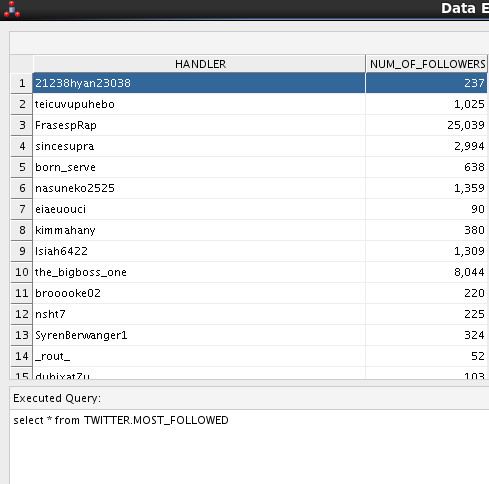
This is NOT the end of the story, it’s in fact the foundation. I’m not a BI guy or have anything to do with analytics, but anyone with a solid foundation knows the possibilities of what I’ve just created. See, Oracle Data Integration Solutions helps you transform business by moving data and building the right foundation.
Conclusion
Oracle Data Integrator is Big Data ready, I was able to implement data transformation within Hadoop itself using ODI, then moving the results into a relational database, Oracle. I didn’t need to code anything in ODI in order to execute my interfaces, it was purely drag/drop and options selection.
Follow me here and on Twitter @iHijazi to stay posted.
Issam